文馨贤
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
21 世纪以来,中国金融市场蓬勃发展。越来越多的普通人成为了初级投资者,进入金融市场寻求机会;
同时金融机构也在不断地寻找有效的分析方法和工具,优化在可控投资风险范围内的投资回报,其中对价格序列的预测是一个研究重点。
随着人工智能技术的快速发展,利用深度学习的金融资产价格预测也成为目前热门的研究方向之一。文献[1]构建了多层的双向LSTM 模型,双向单层的LSTM 模型在黄金期货每日价格序列预测中相对效果更好。文献[2]引入堆叠的去噪自编码模块对恒生指数交易数据和技术指标提取特征,将其作为LSTM 的输入实现收盘价预测。
基于循环神经网络(RNN)类的模型存在梯度消失和长期依赖问题,且没有并行处理能力,研究人员考虑了结合卷积神经网络(CNN)和RNN 的混合模型。文献[3]使用CNN 对纽交所每日股票交易数据进行局部特征提取,采用LSTM 获取长期依赖特征,将两个模块特征进行融合以预测趋势。针对高频数据的研究,文献[4]结合CNN 和LSTM 以及注意力机制,使用CNN 对序列提取初步特征,通过LSTM 进一步提取时序特征,并引入注意力机制来获取加权的权重。实验表明,混合模型在沪铜期货的价格预测上有一定效果。文献[5]使用CNN和基于注意力的BiLSTM 分别在空间维度和时间维度上提取特征,实验表明混合模型效果好于单一模型。
分钟、小时级别采样频率的高频数据是非平稳高噪声的。针对高噪声问题,有研究提出用“先分解后重构”的方法对数据进行预处理,并结合深度学习构建模型。文献[6]针对原油期货,提出使用集成经验模态分解(EEMD)序列去噪后重构,使用ARIMA、LSTM 组合方式对价格序列进行预测,在日度序列上能达到一定效果。文献[7]采用EEMD 对价格序列分解后的不同内涵模态分量构建GRU网络分别进行预测,并对预测结果求和。模型预测效果一般,但相比使用LSTM 结构,效率有提升。
当前期货高频价格序列预测的研究存在以下几个挑战:研究主要以低频数据为主,针对期货交易特点的高频数据研究不足。高频价格序列具有非线性、高噪声的特性,数据体量大、建模困难,当前相关研究预测准确度不够。
本文提出的CEEMDAN_Linformer 模型,使用自适应噪声完全集成经验模态分解(CEEMDAN)对期货高频价格序列数据进行去噪预处理。使用CEEMDAN 是因为经验模态分解存在模态混叠问题,CEEMDAN 可以通过自适应噪声更好地缓解该问题。同时,将时间戳融合到模型输入中,使模型能获得全局特征,使用线性时间复杂度的带傅里叶变换的线性Transformer 对输入特征进行提取。本文提出的模型在预测效率和效果上好于其他基准模型。
1.1 问题定义
本文的期货价格序列预测任务为有监督学习任务。模型输入的第一个样本为离散时间序列T1={x1,x2,…,xN},xt是t时刻的序列数据值。使用滑动窗口固定长度为N的滑动窗口机制,设滑动窗口的滑动步长为1,模型的第i个输入样本为Ti= { }xi,xi+1,…,xi+N-1。为了实现模型输出的多步预测,设预测的步长为k,将输入序列中后k步数值置零,则模型的输入为Ti={xi,xi+1,…,xi+N-1-k,0,…,0 },对 应 的 输 出 为Oi={yi,yi+1,…,yi+N-1},其中,模型预测的k步步长序列为{yi+N-k,…,yi+N-1}。经滑动窗口获得的一系列输入样本还需要经过标准化处理,再作为模型输入进行输入编码。
1.2 数据去噪
本文中分钟级别和小时级别的序列数据属于高频数据,高频数据含有大量噪声,对模型预测的准确率有一定影响,因此在作为模型输入前需对数据进行去噪、标准化等预处理。
本文采用对序列先分解后重构的思路进行去噪。使用基于自适应噪声的完全集成经验模态分解(CEEMDAN),在EMD 基础上添加自适应的白噪声序列,在保障原始数据完备的情况下,有效缓解了分解后模态混叠的问题。对原始序列分解后,获得m个内涵模态分量(IMF),经过实验去除其中高频部分,再将其余所有的分量叠加,完成序列重构,以实现对序列数值的去噪。
CEEMDAN 分解过程如下:
3)设EMD 分解为fk(·) ,对第k次实验,第k个IMF和第k个剩余分量为:
4)重复以上操作,直到剩余分量无法再被继续分解为止,最终得到原始序列被分解为m个IMF和一个趋势项。
1.3 模型结构
本文的模型是典型的Encoder-Decoder 架构,主架构由一个Encoder和一个Decoder组成。经过CEEMDAN去噪后的输入序列,通过输入编码模块(Input Embedding)获得输入向量,作为Encoder 的输入;
Decoder 的输入包括两部分,即Encoder的输出和对应标签经过输入编码模块后的输入向量,Decoder对两部分输入进一步提取特征。
在本文中Encoder 由4 个相同的Encoder block 组成,每个Encoder block 中包含一个傅里叶变换模块(Fourier Transform)提取特征,经过层归一化[8](Layer Norm)和残差连接[9](Add),进入一个位置前馈网络(FFN)后再通过一次层归一化和残差连接结构获得Encoder block 的输出。Decoder 由1 个Decoder block 组成,每个Decoder block 由带Mask 的多头注意力模块(Multi-head Attention)、位置前馈网络、层归一化、残差连接构成。Decoder 中使用Mask Multi-head Attention 是为了防止数据泄露。模型整体结构如图1 所示。
1.4 输入编码
模型的输入编码包括三部分:序列数值编码(Data Embedding)、位置编码(Position Embedding)、时间戳编码(Timestamp Embedding)。对于数值部分,使用卷积核为3 的一维卷积网络提取局部特征,得到序列数值编码向量。同时,为了使模型捕获输入序列的顺序性信息,加入对输入序列的位置编码来得到输入的顺序特征。在价格序列中除了序列数据数值外,对应的时间戳也是输入特征的一部分,故引入对时间戳的编码,为输入引入了时间的全局特征。价格序列的时间戳包含年、月、日、星期、小时、分钟等信息,依次对其进行编码后合并。将序列数值编码、序列位置编码、时间戳编码进行融合后,得到最终的输入编码向量。具体结构如图1 中Input Embedding 所示。
获得输入编码为:
1.5 傅里叶变换模块
多头注意力机制中涉及的矩阵运算使得模型的时间复杂度为平方级,为了降低模型复杂度,使其更好适应于规模不大的数据集,本文将Encoder block 中的多头注意力模块替换成线性傅里叶变换。
设隐含层维度为dm,序列长度为N,Transformer 在长序列输入的情况下,自注意力计算需要N×N的注意力分布矩阵的存储空间,自注意力模块会造成模型性能的瓶颈[10]。
本文中的价格序列为时域上频率小时、分钟的离散价格数据,适用于离散傅里叶变换:
模型的输入编码向量维度为[Batch_size,ds,df],对序列长度维度ds进行傅里叶变换,相当于在该维度上将序列分解为多个正弦波叠加形式;
再对特征变量维度df进行傅里叶变换,在特征变量维度上再次分解为正弦波叠加形式。
通过对不同维度的两次傅里叶变换,把时域的序列转化到了频域再进行特征提取,即二维傅里叶变换。本文中使用的线性Transformer,用傅里叶变换模块替代了多头自注意力机制。这种没有引入参数的线性结构,不但不会增加模型的复杂度,同时将模型的复杂度降低到线性级别。
2.1 实验配置
2.1.1 实验环境
实验使用Nvidia Tesla T4 显卡16 GB 内存,开发语言Python 3.9,模型构建采用深度学习框架Pytorch 1.9.0。
2.1.2 数据集
本实验对贵金属期货品种——黄金期货、白银期货的高频价格序列数据进行研究。取上海期货交易所黄金期货和白银期货的长期主力合约——6 月合约历史交易数据构建采样频率分别为5 min、1 h 的4 个数据集。数据源来自万得金融数据库。数据集具体内容见表1。
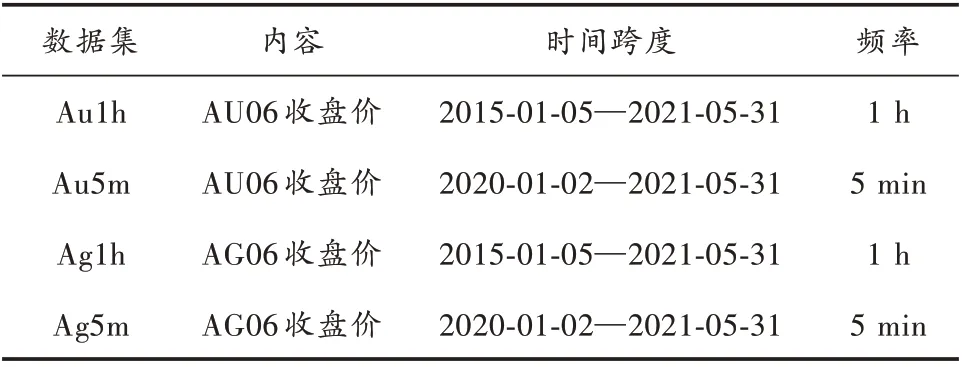
表1 数据集描述
实验中每个数据集的训练集和测试集的划分比例为8∶2,滑动窗口大小设置为100,滑动窗口步长为1。
2.1.3 评价指标
本实验中使用的三种评估标准对模型性能进行评估,分别是均方误差(MSE)、平均绝对误差(MAE)、均方根误差(RMSE),具体公式如下:
2.1.4 比较基准
实验将使用序列预测任务中常用的基准模型:LSTM、CONVLSTM、TCN、Transformer 与本文提出的模型进行对比实验。
LSTM:长短时记忆网络为时间序列预测常用模型,实验构建4 个LSTM 子层,最后使用一个全连接层,得到预测结果。
CONVLSTM[11]:在时空序列预测应用中首次提出,是结合CNN 和LSTM 的混合模型。通过将LSTM 门控单元部分操作更换为卷积,使用堆叠的CONVLSTM block构建了基于编码的端到端的预测架构。实验中模型由一个CONVLSTM 层和一个LSTM 层构建。
TCN[12]:使用因果膨胀卷积和残差网络的时域卷积网络。为了获取到较长的历史输入数据,使用了膨胀卷积,指数级地增加膨胀系数,并通过残差连接来优化深度的网络。
Transformer[13]:模 型 是Encoder-Decoder 架 构,Encoder 和Decoder 中使用多头注意力机制,在获取全局特征的情况下又能做到并行计算。
2.2 参数设置
本文提出的CEEMDAN_Linformer是基于CEEMDAN分解去噪的线性Transformer,应用于期货高频价格序列的多步预测。模型最优参数设置具体如表2 所示。

表2 参数设置
2.3 数据去噪
实验对数据集进行去噪预处理,以Au5m 数据集为例,使用CEEMDAN 分解后的结果如图2 所示。使用CEEMDAN 将原序列分解为11 个IMF 和一个残差项,由图2 可知,前6 个内涵模态分量IMF1~IMF6 为高频分量,幅度在(-5,5)之间。本文通过去除部分高频IMF,再对剩余分量叠加重构的方法实现数据去噪。经过实验对比,选择重构参数为2 时,对序列进行重构去噪效果最佳。
2.4 实验结果对比与分析
本文提出的CEEMDAN_Linformer 及四个基准模型在黄金期货、白银期货的不同采样频率的收盘价序列构成的4 个数据集上进行对比实验。实验均设置输入样本步长为100,预测步长为5,即在小时采样频率数据集上使用过去100 h 收盘价,来预测未来5 h 收盘价;
在5 min 采样频率数据集上使用过去500 min 收盘价,来预测未来25 min 收盘价。
CEEMDAN_Linformer 及四个基准模型在三个评价指标MAE、MSE、RMSE 中的对比如表3 所示。在小时级数 据 集 上,CEEMDAN_Linformer 和Transformer 的 预 测误差远小于其他模型,相比其他模型预测误差有较大提升,这说明基于Encoder-Decoder 的Transformer 架构在时间序列预测上有较大的优势。两个模型的预测误差十分接近,CEEMDAN_Linformer 取得了与Transformer接近的性能。主要原因考虑在采样频率为小时时,与分钟采样频率的数据相比,噪声相对较小,CEEMDAN_Linformer 的优势不明显,但其在降低了模型复杂度的情况下,仍然保持了与Transformr 相当的特征提取能力。

表3 模型性能对比
在分钟级别数据集上,CEEMDAN_Linformer、Transformer和CONVLSTM 均有较好的预测效果。其中,CEEMDAN_Linformer 预测误差最优,相较于Transformer仍有较大的提升,说明在高频序列的预测上CEEMDAN_Linformer 相较于Transformer 更优。这主要是由于CEEMDAN_Linformer 考虑了高采样频率数据的去噪,捕获局部特征的同时充分考虑时间维度上的全局特征。通过实验结果也可以看出,传统的RNN 类模型——LSTM 在高频序列的预测上不太适用,不同数据集上预测误差均较大。综上,CEEMDAN_Linformer 在采样频率分钟级别、小时级别的多步预测任务上是有效的,尤其在采样频率更高的任务中表现更为优异。
图3 是模型在Au5m 测试集上的预测结果(归一化后),虚线表示真实值和预测值之差。从实验结果看出,模型能够预测序列整体变化趋势,预测值趋势与真实趋势基本一致。在价格序列短期波动较大时,预测误差存在进一步提升空间,但在价格波动较小时,模型有较好的预测效果。
2.5 参数敏感性实验
Encoder中Encoder block的数量对模型的构建有较大的影响,Encoder block的数量多、模型规模大,容易出现过拟合的情况。图4 是在Au1h 数据集上采用不同数量Encoder block 模型的预测误差实验结果。
根据实验结果得出,随着Encoder block 数量的增加,三个评价指标下降后均开始上升,总体在Encoder block=4 时三个指标误差最小,模型效果最佳。随着Encoder block 数量的再次增加,模型复杂度增大,开始出现过拟合,预测误差反而上升。
2.6 消融实验
将本文提出的模型和使用EMD、EEMD 以及去除去噪模块的Linformer在Au5m 数据集上进行对比实验。设置输入步长均为100,输出步长均为5,实验结果见表4。

表4 不同去噪方法效果对比
实验结果表明,相比不使用去噪模块,使用CEEMDAN 模块去噪对模型整体预测误差降低了44.96%。使用EMD 和EEMD 去噪后重构序列进行预测的效果不如本文模型。通过实验发现,加入了EMD 和EEMD 去噪模块的模型,比不使用去噪模块的Linformer预测误差更大。这表明EMD 和EEMD 的引入不但对模型预测没有提升,反而会导致预测准确率严重下降。分析原因是由于EMD 和EEMD 分解时出现模态混叠情况较严重,重构后序列与原序列有较大差异,破坏了原序列的特征,使数据的可学习性降低。
价格序列的预测能够为投资决策、投资组合交易等应用中提供相应的决策支持。本文针对金融领域期货高频价格序列噪声大、预测困难等问题,提出了CEEMDAN_Linformer 模型来实现多步价格序列预测。模型使用CEEMDAN 对期货高频时间序列的大量噪声进行去噪预处理,输入编码中融合时间戳作为全局特征,结合线性Transformer 实现在分钟级别和小时级别序列的多步价格序列预测。相比其他基准模型,本文提出的模型整体预测效果较好,并在采样频率较高时表现更好。本文实现了利用单变量输入预测单变量问题,即使用期货收盘价作为单一输入对未来多个时间步的收盘价进行预测。针对多变量特征作为输入,进行单变量或多变量多步的预测问题是本文下一步的研究方向。
猜你喜欢 模态编码误差 联合仿真在某车型LGF/PP尾门模态仿真上的应用汽车实用技术(2022年10期)2022-06-09多模态超声监测DBD移植肾的临床应用昆明医科大学学报(2022年3期)2022-04-19生活中的编码小学生学习指导(中年级)(2021年12期)2021-12-30跨模态通信理论及关键技术初探中国传媒大学学报(自然科学版)(2021年1期)2021-06-09《全元诗》未编码疑难字考辨十五则汉字汉语研究(2020年2期)2020-08-13子带编码在图像压缩编码中的应用电子制作(2019年22期)2020-01-14Genome and healthcare疯狂英语·新读写(2018年3期)2018-11-29隧道横向贯通误差估算与应用智富时代(2018年5期)2018-07-18隧道横向贯通误差估算与应用智富时代(2018年5期)2018-07-18精确与误差中学生数理化·七年级数学人教版(2016年6期)2016-05-14