朱嘉豪 ,张玉书 ,刘 哲 ,张新鹏
1 南京航空航天大学计算机科学与技术学院 南京 中国 211106
2 复旦大学计算机科学与技术学院 上海 中国 200433
随着互联网的普及与发展,信息传递与交流方式日益多样,信息量也呈指数式增长。不法分子凭借便捷的传播途径并以文本、图片、视频、音频等媒介为载体进行不良信息传播,对国家网络空间安全造成严重的危害[1]。因此,针对这些媒介的内容过滤系统应运而生。文本作为互联网信息传递与信息交流的重要载体,在互联网中的使用最为广泛,针对文本信息过滤的研究已然成为信息过滤领域中的研究重点。信息过滤这一概念最早由Denning 在1982年提出[2],作者以电子邮件为特例,描述了如何利用过滤机制对重要邮件和普通邮件进行识别。起初,针对文本的过滤大多依靠简单的关键词匹配算法[3-5],这类算法具有较快的过滤速度,然而并没有考虑到字词与上下文的关联性。此外,一些文本内容散布者会有意避开使用敏感词,这便使得基于关键词匹配的信息过滤算法失效。随着自然语言处理技术的发展,基于内容理解的过滤算法逐渐成为文本过滤的研究重点。研究者开始对文本中的字、词和短语等文本基本单元(即特征项)进行划分,并进行一系列特征提取操作以获取具有判别文本内容性质的特征集[6-7],主要步骤包括: 文本特征项分离、文本特征项量化,以及文本特征项筛选与提取。面对海量文本特征集合,学者们纷纷提出了不同的文本内容匹配模型。早些年,贝叶斯决策[8-10]、向量空间[11-12]、支持向量机[13-15]等模型被广泛利用于文本过滤领域。现如今,随着人工智能兴起,深度学习在文本分析领域发挥着不可或缺的作用,文本信息过滤领域也因此取得了新的突破[16-17]。以上文本过滤方案虽然在一定程度上净化了网络环境,然而,互联网中仍存在着信息过滤系统误判或者恶意拦截的问题,例如,社交网络平台之间的链接屏蔽。这类拦截问题严重影响了用户体验,损害了用户权益,扰乱了市场秩序。目前,在中文文本信息过滤领域中,“火星文”在躲避关键词屏蔽方面效果显著,例如,淘宝、拼多多等电商平台为避免商品分享链接被QQ、微信等社交软件拦截而使用“火星文”,如图1(a)所示。然而,随着检测技术的发展,这类利用“火星文”的分享链接仍然存在着被拦截的可能[18]。针对图1(a)所示的分享链接,技术人员可通过对口令“¥PKMAcWP9cyX¥”进行模式匹配从而拦截此类关键信息,这是由于其呈现模式通常具有一定的规律性,易被机器检测。为了有效应对这类文本信息拦截问题,本文设计出了一个针对性的文本信息隐藏系统。

图1 网络中的“火星文”Figure 1 “Martian” in the Internet
信息隐藏作为保障信息传递安全的一种重要技术手段,对国家网络空间安全具有重要意义。目前,传统中文文本的信息隐藏可分为三类,即基于文本图像的算法[19-21]、基于文本格式的算法[22-29],以及基于文本内容的算法,其中基于文本内容的算法又可分为基于语义的算法[30-31]、基于语法的算法[32-33],以及基于汉字结构特征的算法[34-38]。近些年来,凭借文本生成进行信息隐藏的算法逐渐成为主流[39-45]。然而,以上文本信息隐藏算法所生成的含密文本大多以传统平面媒介语言形式呈现,因此,并不适用于规避文本内容拦截,并且这些算法大多基于对原始文本进行微小的修改,存在着嵌入容量小鲁棒性弱的缺点。因此,如何设计出一个能够规避文本信息拦截且具有良好隐写性能的文本隐写系统便成为亟待解决的问题。
目前,尚未存在成熟的技术手段可有效过滤含有“火星文”的文本。在研究过程中我们发现,相较于传统平面媒介语言形式,“火星文”具有更多的冗余空间。因此,本文将“火星文”作为隐写载体,提出了一种可规避文本信息拦截的“火星文”生成隐写系统。该文本隐写系统由预处理、控制以及隐写三大基本模块组成。通过对汉字结构特征的研究以及“火星文”构字方式的分析,本文设计出6 种隐写子模块以供信息嵌入与提取。本文主要贡献有:
(1) 针对互联网中文本信息误拦截以及恶意拦截问题提供了一个实际的解决方案。
(2) 将“火星文”作为隐写载体,提出了基于“火星文”生成的文本隐写系统。该隐写系统较与同类型文本信息隐藏方案在嵌入容量上提高了52%,中文单字符嵌入容量可达1.87 比特,且与基于文本生成的算法相比,该隐写系统又具有较强的鲁棒性。
本文的剩余内容如下: 第二节将介绍中文文本信息隐藏,“火星文”以及汉字的编码的相关知识;第三节描述了“火星文”生成隐写系统的大致框架,并简单介绍信息嵌入流程与信息提取流程;第四节将详细介绍该隐写系统各个模块及子模块的功能;第五节将对实验结果进行分析;最后,在第六节进行总结并展望未来的研究。
2.1 中文文本信息隐藏
信息隐藏作为保障信息传递安全的一种重要技术手段,其利用人类感官冗余与载体数据冗余,将信息以特定方式嵌入至所选载体中,从而实现隐蔽通信[46]。如今,以图片、视频、音频为载体的信息隐藏研究已取得不少学术成果。然而,文本信息隐藏研究显得相对滞后,其中针对中文文本信息隐藏的研究更是少之又少。虽然与图片、视频、音频等载体相比,文本存在着信息冗余度低、数据量少的缺点,但作为互联网信息传递与交流的重要载体,以文本为载体的信息隐藏仍具有一定的研究价值。在中文文本信息隐藏中,部分研究人员将文本存储为图像格式,从而对文本图像进行隐藏操作。Zhao 等[19]通过改变每行文本图像中上下两半部分黑色像素之和的比值进行隐藏操作。该嵌入算法具有较强的稳健性,然而嵌入容量受限于文本行数。Qi 等[20]针对扫描打印文本,通过翻转字符图像黑色点来进行信息嵌入,此算法具有较高的隐蔽性,然而嵌入容量低。Tan等[21]利用傅里叶描述子,通过修改扫描文本图像中字符边界点来进行信息嵌入,进一步提升了隐写容量和鲁棒性。由于对文本图像进行信息隐藏操作并没有充分利用到文本的属性,因此,部分研究学者开始从文本内容的组织方式中探寻冗余空间。其中,一部分算法利用Word[22]、PDF[23]、XML[24]等文档中未使用空间进行信息嵌入,一部分算法通过修改字、行和段在文本中的排版间距进行信息隐藏,如文献[25]。然而,这类算法对文件格式的依赖性极高,且隐藏位置暴露的概率较高。除此之外,一些研究者利用字符的属性进行信息操作,如: 字符编码[26]、字符色彩[27]、字符不可见性[28-29]等,这类算法的嵌入容量普遍高于基于调整文本间距的隐藏算法,然而伴随着隐蔽性差的缺点。随着自然语言处理技术的发展,中文文本信息隐藏逐渐关注文本的内容。其中基于语义的信息隐藏技术主要以同义词替换为主[30-31]。这类算法的嵌入能力往往取决可供替换的词汇数量。针对语法的文本信息隐藏主要从句式以及词性着手进行信息隐藏[32-33]。这些算法具有较强的隐蔽性,然而嵌入能力较差。由于基于语义与语法的信息隐藏算法普遍依赖于自然语言处理技术,在嵌入操作前往往会对文本中的字、词以及句进行分析,从而产生复杂的计算过程。因此,部分学者转而利用中文汉字的特征进行信息嵌入。Sun 等[34]利用文本中左右结构形式作为嵌入位置,Wang 等[35]在Sun 的基础上增加了上下结构汉字的形式作为信息嵌入点。文献[36]通过简繁体的交错使用进行信息嵌入,并提出了简单替换嵌入算法、高效替换嵌入算法以及基于模板的嵌入算法。文献[37]提出一种基于多音字的文本水印方法,文献[38]给出了一种基于汉字笔画的文本水印算法。
以上算法的隐藏操作普遍依赖于原始文本,在文本信息隐藏领域中,存在着不依赖于原始文本的隐藏算法,即文本生成隐写。在中文文本生成隐写算法中,以诗词为隐写载体的构造式文本信息隐藏成为了研究热点。Yu 等[39]最先将宋词作为隐写载体,其提取不同的宋词格律模板并根据待嵌信息生成含密宋词,然而,所生成的宋词质量不高且信息嵌入率较低。Liu 等[40]对文献[39]所提出的算法做出改进,提高了信息嵌入率,然而宋词生成质量仍然不佳。为了提高所生成诗词的质量,Luo 等[41]提出了基于马尔科夫链的宋词生成模型。随着深度学习的发展,基于深度神经网络的诗词生成隐写模型也被设计出[42-43],这进一步提高了生成质量以及信息嵌入率。此外,Yang 等[44]设计出一种基于循环神经网络的语言隐写术,其可根据待嵌秘密比特流自动生成英文文本,同时也适用于中文。然而,所生成的文本质量并不能完全保证隐写的安全性,因此,Yang 等[45]又提出基于变分自编码器文本隐写方案,进一步提升了隐写文本的隐蔽性和安全性。
2.2 隐写载体——“火星文”
“火星文”作为网络语言的一种存在形式,是网络语言发展到一定阶段的产物,其普遍存在于互联网中[47]。早期的“火星文”是社会青年群体为追求个性、新颖而设计出的语言符号,如图1(b)所示。现如今,“火星文”又增添了新的用途,其被广泛用于躲避关键词屏蔽,例如淘宝、拼多多等网购零售平台为避免商品分享信、QQ 等社交软件拦截而使用“火星文”,如图1(a)所示。“火星文”字符种类繁多,构字复杂多样。目前,“火星文”常见的构成方式有如下5 种: 网络符号构成、数字组合构成、拼音字母构成、简繁体汉字构成,以及生造字构成。由于人具有认知推理能力,在“火星文”中,任意常规汉字可以由多种方式进行表示且不影响人的理解,例如汉字“皓”,可被转化为拼音“hao”,也可被拆分成汉字“白”与“告”,亦或是被替换偏旁生成“浩”。因此,较于传统平面媒介的语言形式,“火星文”具有更高的信息冗余度,也存在更大的空间可供秘密信息嵌入。
2.3 汉字编码
对汉字进行有效的编码可使汉字的操作与处理更为简便。Sun 等[48]提出了一种汉字编码方式,使汉字能够以简便的数学形式呈现。不失一般性,设Ω为汉字集合,Θ为汉字部件集合,Ξ为Θ中任意两个汉字部件位置关系集合,则存在如下两种情况:
•Θ={“点”,“横”,“竖”,“撇”,“捺”,“折”,“钩”,“提”},则Ω=(Θ,Ξ)。
•Θ=Ω,Ξ=∅,则Ω=(Θ,Ξ)。
第一种情况下,Θ为8 种汉字基本笔画,构造最为简单,任意汉字部件可由此8 种笔画组合而成。然而,汉字部件繁杂,组合方式繁多。因此,位置关系集合Ξ便极其复杂。第二种情况下,Ξ为空集,则Θ为整个汉字集合Ω,这便使得Θ中的元素过多。为了平衡Θ与Ξ构造时的复杂度问题,作者对汉字的组成部件进行了统计分析,从中选取了505 个汉字部件作为集合Θ的元素,图2 展示了部分汉字部件的编码。针对此505 个汉字基本部件,作者进而定义了6 种汉字部件空间位置关系作为集合Ξ的元素,如图3 所示。将Θ中的元素作为操作对象,Ξ中的元素作为操作符,根据表1 所提供的符号优先级以及运算方向,则每个汉字都有其唯一的编码形式。本文选取了2500 个常用简体汉字,记为Ωsc,其对应的繁体字集合为Ωsc,且有Ωsc∪Ωtc=Ω。图4 展现了部分所选简体字表达式。

图2 汉字部件编码Figure 2 Chinese character component codes

图3 汉字部件的6 种空间关系Figure 3 Six spatial structures between Chinese character components
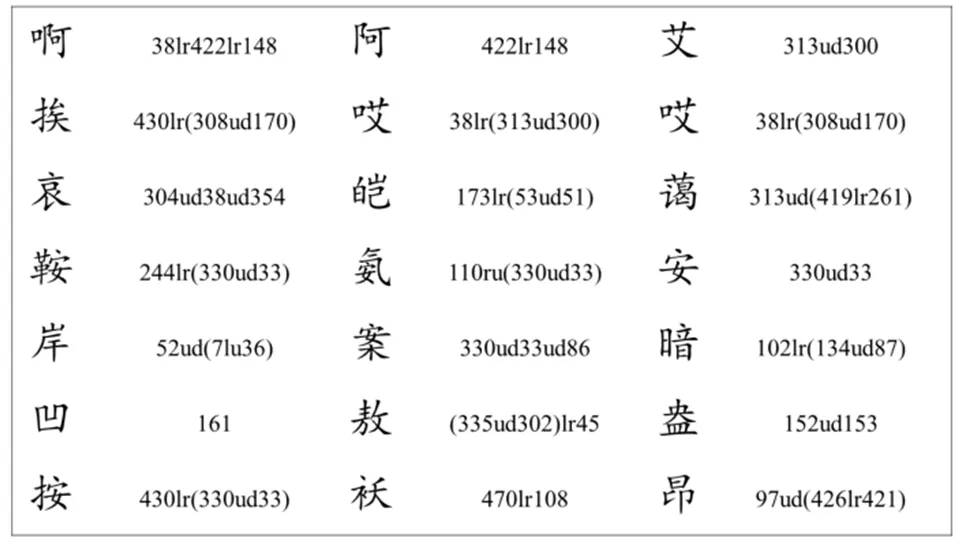
图4 汉字编码Figure 4 Chinese character codes

表1 算符优先级表Table 1 Operator priority table
本文提出的隐写系统主要由三大模块组成: 预处理模块、控制模块,以及隐写模块。根据“火星文”的构字方式,本文设计出6 种隐写子模块,分别为:简繁体转换模块(s-t transformation,S-TT)、字音转换模块(c-p transformation,C-PT)、字体重构模块(font reconstruction,FR)、同音字替换模块(homophone substitution,HS)、字体拆分模块(font separation,FS)以及非汉字字符替换模块(non-Chinese character substitution,N-CCS),如图5 所示。根据以上模块的设计该文本隐写系统的信息嵌入过程如图6(a)所示。首先选取原始文本,与此同时,将待嵌信息输入至预处理模块进行数据规范化。将原始文本与预处理后的待嵌信息作为控制模块的输入,控制模块会根据待嵌信息的内容并结合输入字符的特征将隐写任务分配至相应的隐写子模块中。最后,隐写子模块执行信息嵌操作,并将反馈信息传递至控制模块以便执行下一步信息嵌入操作。图6(b)描述了该文本隐写系统信息提取流程。首先获取含密文本“火星文”,判断当前含密字符的类型。控制模块会根据含密载体字符的类型将信息提取任务分配至相应的隐写子模块中。最后,隐写子模块执行相应的信息提取操作,并将反馈信息发送至控制模块,以便控制模块执行下一步信息提取操作。其中,隐写模块中的标号表示为其所对应的隐写子模块,控制模块在信息嵌入与提取过程中的任务分配细节将在第四节讨论。
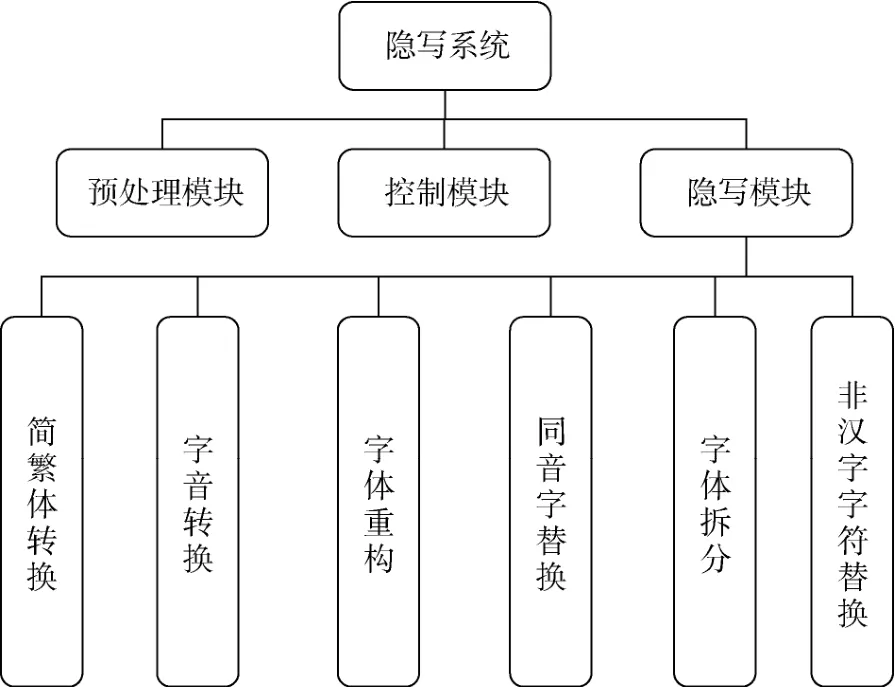
图5 “火星文”隐写系统框架Figure 5 Steganographic framework of“Martian”system

图6 信息嵌入与提取流程图Figure 6 Flow chart of information embedding and extraction
此节将详细描述该文本隐写系统的各个模块的功能以及算法实现。不失一般性,设英文字符集E,数字集合为N,标点符号集合为Ψ,原始输入C={c1,…,cn},其 中ci∈E∪N∪Ψ∪Ωsc,待 嵌信息为M,M={0,1}q,q为待嵌消息的长度,含密文本为S,S={s1,…,sd},其中si为“火星文”字符。值得注意的是,标点符号不进行信息嵌入与提取处理。
4.1 预处理模块
该模块主要负责以下两个部分工作:
4.1.1 辅助信息增添
信息嵌入过程中,C中字符可能会遗留部分未被使用,这会给信息提取带来操作上的不便。为了解决此问题,本文采取如下步骤:
Step 1: 计算M的长度l。
Step 2: 将l转换为二进制lb,若lb不足λ位,则采取高位补0。
Step 3: 生成预处理信息M",M"=lb∪M。
4.1.2 待嵌信息加密
为了保证秘密信息内容的隐私性,首先应对待嵌信息M′进行加密,得到密文信息比特流Me,

其中,K为密钥,P为辅助参数。所选择的加密方案只需满足如下等式即可
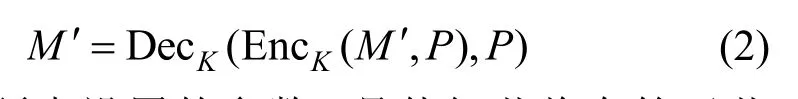
其中,λ是预先设置的参数,具体细节将在第五节讨论。
4.2 控制模块
此模块主要负责解决信息嵌入以及信息提取过程中任务分配的问题,任务分配细节如下。
4.2.1 信息嵌入任务分配
为解决简繁体字信息提取过程中的混淆问题,例如简繁体转化模块与字体重构模块都有可能生成简体字,则必定会给信息提取带来困扰,因此,须在每一次隐写操作过程中引入一个隐写控制符。本文采用了Unicode 不可见控制字符(零宽度字符)[29]。由于原始字符ci∈E∪N∪Ψ∪Ωsc,这些不可见控制字符并不会对文本的显示造成太大的影响。为了增加隐写容量,使引入的不可见控制字符也能携带信息,我们对其进行了编码。表2 显示了不可见控制字符Cinvisible的编码和所属类别的标号,并给出所适用的隐写子模块。然而,使用以上特殊Unicode 字符存在着隐写安全性问题,在第五节中,我们将对其进行分析,并给出一种可行的解决方案。在每轮信息嵌入中,信息嵌入方式取决于随机数α的值,α∈ (0,1)。为了表达简便,设当前待嵌字符为ci,待嵌信息比特为mj,Modulek,k=1,… ,6,对应6 个隐写子模块且接受参数ci与Cinvisible,Cinvisible的取值由表2 与待嵌比特串 {mj,mj+1}得出,I1、I2和I3分别表示表2 中第一类、第二类与第三类Unicode 不可见控制字符集合,设fs为反馈信号。例如,当α的值落入Module3也就是字体重构模块的判定域中,则控制模块会选取Module3进行信息嵌入操作。由表2 可知,Module3适用于第2 类不可见控制字符,因此,控制模块根据{mj,mj+1}的值选取对应的不可见控制字符Cinvisible并将其作为参数与ci一并传入至Module3。图7 左部分展示了信息嵌入任务分配流程。参数εi的设置将在第五节讨论。

图7 信息嵌入与提取任务分配流程Figure 7 Allocation processes of information embedding and extraction task
4.2.2 信息提取任务分配
在信息提取过程中,控制模块首先判别含密字符si的字符类型,若为不可见控制字符,则可根据表2 查找其所属类别和对应的隐写子模块Modulek,继而将si作为参数分配至该隐写子模块。否则,将根据si的是否为汉字进行信息提取时的任务分配。图7右部分展示了信息提取时的任务分配流程,由图可知,无论si的字符类型如何,其都会作为参数传入至Modulek。由于控制模块已经对si做出判断,对于各个隐写子模块Modulek而言,所接受的字符si的类型是已知的。
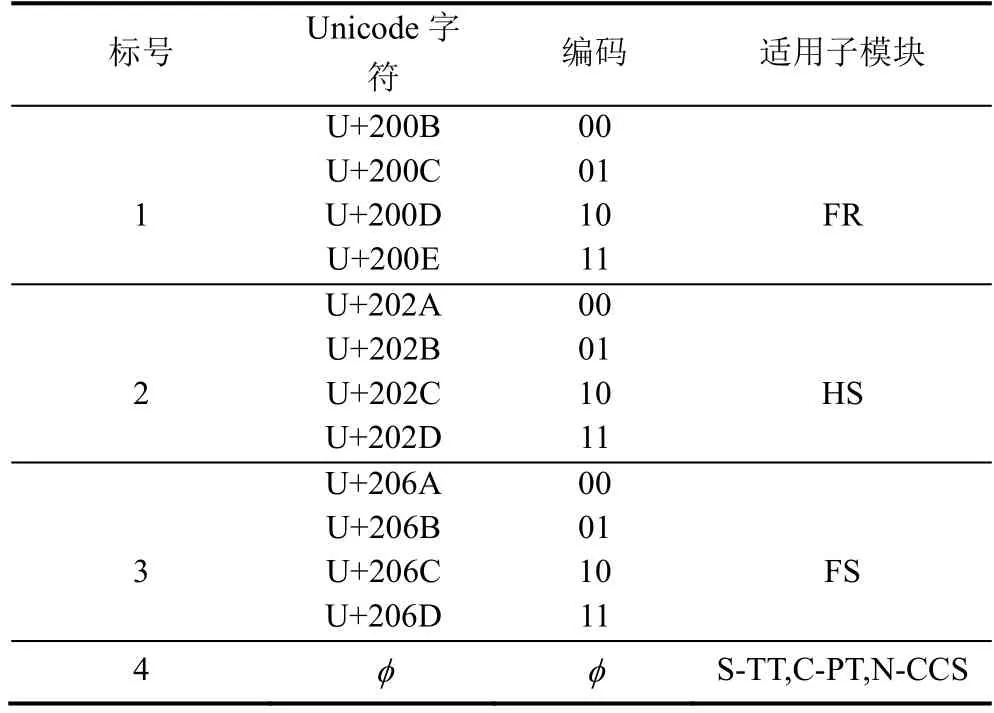
表2 隐写控制字符表Table 2 Steganographic control character table
4.3 隐写模块
“火星文”字符种类繁多且构字复杂多样,本文通过对汉字结构特征的研究以及“火星文”构字方式的分析,设计出如下6 种隐写子模块:
4.3.1 简繁体转换模块
Sun 等[36]提出了三种针对简繁体的信息嵌入方式,即简单替换嵌入算法(SSE)、高效替换嵌入法(ESE)以及基于模板的嵌入算法(TBE)。为了保证较高的嵌入率,同时又兼容其他隐写子模块,本文参考SSE 算法,并设计字典D:Ωsc→Ωtc,信息嵌入过程如下:

4.3.2 字音转换模块
简体字与拼音的转化本质为简体字与英文字符的替换,Rizzo 等[49]利用Unicode 协会所提出的“混淆”字符表进行信息嵌入,该方案对字符的外形相似度具有较高要求。然而,“火星文”对字符的相似度约束更加宽泛,只需满足外形相似或者语义相似即可。本文并没有对相似字符表中的具体内容做出约束,只需满足通信双方的约定即可,表3 显示了部分相似字符以及对应编码,算法1 展示了信息嵌入过程。

表3 相似字符表Table 3 Similar character table
算法1.字音转换信息嵌入算法.

对于信息提取,只需在表3 中查找当前含密字符si所对应的编码即为提取信息mj。
4.3.3 字体重构模块
在“火星文”中,字体重构的表现形式分为两种,第一种为偏旁增添,如: 打→咑,第二种为偏旁替换,如: 嗷→遨,然而无论是偏旁增添还是偏旁替换,为了不造成过大的感官差异,增添或替换的偏旁对于整个汉字的其他部件而言应在结构上显得更加简单,笔画数更少。根据第二节所介绍的汉字编码知识,本文采用一种汉字的二叉树表示形式,图8 展示了部分汉字的树形结构。为简便表达,设α,β∈Θ*,f(·)为求笔画数函数,h(·) 为求树高函数,且有如下定义:

图8 汉字的树形结构Figure 8 Tree structure of Chinese characters
定义1.若h(β)-h(α)≤θ1,定义:β≼Hα。
定义2.若f(β)-f(α)≤θ2,定义:β≼Sα。
其中参数θ1、θ2的设置将在第五节进行讨论。
本文在Θ上建立一个以汉字部件笔画数为索引的字符表Γ,并遵从如下两个设计准则:
• 汉字部件笔画数的分类应使得表中每行元素分配尽可能均匀。
• 汉字部件笔画数的分类应使得表中每行元素尽可能多。
考虑到单字符嵌入容量对系统鲁棒性的影响,本文对505 个汉字部件笔画数进行了统计,对Γ 进行如表4 所示的设计。算法2 展示了偏旁增添情况下信息嵌入的过程。算法3 则适用于偏旁替换情况下的信息嵌入。在具体的信息嵌入操作中,该隐写子模块会优先执行偏旁增添信息嵌入算法,若此算法失败则执行偏旁替换信息嵌入算法。

表4 以笔画数为索引的汉字部件表Table 4 Chinese character component table indexed by stroke number
信息提取过程中,由于已经知道当前含密字符si为不可见控制字符,因此si+1必定为经过偏旁增添或者偏旁替换修改过的汉字,具体的信息提取过程如算法4 所示。
算法2.偏旁增添信息嵌入算法.

算法3.偏旁替换信息嵌入算法.

算法4.字体重构信息提取算法.

4.3.4 同音字替换模块
同音字替换普遍存在于“火星文”中,且所替换的同音字可为简体字也可为繁体字。本文在Ω=Ωsc∪Ωtc的基础上建立了一张同音字表Σ 以供信息嵌入与提取。对于每个同音字集合,本文提出一种完全二叉树字符编码方案,图9 展示“rèn”集合中汉字的编码方式。值得注意的是,对于一个完全二叉编码树,汉字的编码长度是变化的,并且汉字只存储在叶子节点,其他节点存储的数据都为空。为了解决由一字多音所造成的信息提取失败问题,本文在设计同音字表时,保证相同汉字不会在多行出现。表5 展示同音字表的部分信息,信息嵌入算法如算法5 所示,算法6 描述了Gethomophone 函数。

图9 同音字完全二叉编码树Figure 9 Complete binary coding tree for homophones
算法5.同音字替换信息嵌入算法.


信息提取过程中,当接收到含密字符si,则可知si+1为经过同音字替换模块处理过的汉字,具体信息提取步骤如下:
Step 1:据表2,获取si的编码controlcode。
Step 2:获取si的拼音SPi+1。
Step 3:在表5 中查找SPi+1所在行,在该行检索si+1,并获取si1+的二叉树编码btc。
表5 同音字表Table 5 Homophone table
Step 4: 提取信息mj=controlcode,mj=controlcode∪btc,并将反馈信号fs设置为True 返回至控制模块。
4.3.5 字体拆分模块
根据研究发现,火星文中大部分的拆分字都是左右形式和上下的形式,其中以左右形式的拆分居多,如: 行→彳亍,好→女子。由于上下形式的拆分已经破坏汉字视觉上的结构,一定程度上影响读者的理解,因此本文仅考虑左右结构汉字的拆分,文献[34-35]都提出了针对左右结构汉字的信息嵌入方案。然而,在信息提取过程中,需要生成原始样本作为参考,因此操作复杂,不适用于本文提出的文本隐写系统。具体信息嵌入过程如算法7 所示。
算法7.字体拆分信息嵌入算法.

对于信息提取,当该隐写子模块接收含密字符si,则可根据表2 获取si对应的编码controlcode。同时我们也知si1+与si+2为一个汉字的左右两个部分,依据字体拆分模块的嵌入算法,最后可得mj={controlcode,1}。
4.3.6 非汉字字符替换模块
信息嵌入过程中,该子模块主要利用相似字符表3 对原始生成样本中英文字符或者数字字符采取相似字符替换进行信息嵌入。信息提取过程中,该模块会查找当前含密字符在相似字符表中对应的编码,并做出相应的信息提取操作。具体的嵌入与提取算法与字音转换模块所提供的方法相似,此处不再赘述。
本节首先介绍度量指标的设计,接着对参数设置进行讨论,并依据设定的参数进行实验。在实验结果基础上,进一步分析该文本隐写系统鲁棒性。
5.1 度量指标
不失一般性,设嵌入率为ER,则

其中,M表示嵌入比特,C表示原始文本字符数,设嵌入效率为EE,则

其中CH为原始文本修改字符数。设文本膨胀率为TER,则

其中S为含密样本字符数。值得注意的是,我们并没有利用原始文本比特数与含密文本比特数之比来计算TER,这是由于在不同的编码方案中,字符所占字节数可能并不相同。
文本膨胀会增加信息传输的成本,因此一个良好的文本隐写系统应在具有较高的嵌入率ER 与嵌入效率EE 的同时具有较低的文本膨胀TER,本文给出隐写性能衡量指标
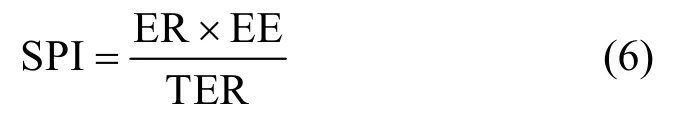
为了与不同类型的文本信息隐藏算法进行比较,本文给出单字符嵌入容量

5.2 隐写子模块嵌入能力分析
本文中,各个隐写子模块的单字符嵌入能力并不相同,按照前文所设计的表,我们可以计算出各个隐写子模块的单字符嵌入容量。对于S-TT 模块,无论是简体字还是繁体字都只嵌入1 比特信息,且没有附加控制字符,因此SCEC(S-TT)=1 比特。对于C-PT 模块,依照相似字符表的编码方案,易得SCEC(C-PT)=2 比特。对于FR 模块,经过偏旁替换或者增添的汉字能嵌入2 比特信息,同时附加的一个控制字符也可嵌入2 比特信息,根据公式(7)可得SCEC(FR)=2 比特。对于FS 模块,由于字体是否拆分取决于当前待嵌比特mj的取值,则可根据公式如下公式计算出FS 模块的单字符嵌入能力:

其中p0与p1分别表示mj=0与mj=1的概率,SCEC(X|Y)表示在情况Y下,模型X的单字符嵌入容量。不妨设p0=p1=0.5,mj=0时,FS 模块相当于S-TT 模块,因此,SCEC(FS|mj=0)=1比特。在mj=1情况下,SCEC(FS|mj=1)=1.5比特,根据公式(8)可得SCEC(FS)=1.25比特。对于N-CCS 模块,根据前文的嵌入算法,易得SCEC(N-CCS)=2比特。HS 模块与以上模块不同,该模块的嵌入能力与一个汉字的同音字个数有关,因此,我们从scΩ随机抽取了100 个汉字,并为每个汉字随机生成了100 个长度为10 的比特串用以模拟待嵌比特流,最后对这10000 组实验结果取均值,表6 给出了各个隐写子模块的具体嵌入能力数据。

表6 各隐写子模块单字符嵌入容量(单位:比特)Table 6 Single character embedding capacity of each steganographic sub module(bit)
5.3 参数设置
若不考虑实际应用,可只选择单字符嵌入能力强的模块进行信息嵌入。然而,这样生成的隐写样本不仅影响人的正常理解,同时也可能暴露系统相关表的信息。为了让本文所提出的隐写系统能够运用于现实生活,所生成的隐写样本需接近网络中的样本。因此,在参数设定上,本文参考了“火星文”在各大网络电商平台“火星文”的使用情况。
5.3.1 预处理模块参数
预处理模块参数λ的取值与待嵌信息长度有关,通常情况下,通信双方会约定传递消息的最大长度,且本文所提出的隐写系统的隐写性能对此参数并不敏感。实验中,本文设置λ=7,即待嵌消息长度最大为128 比特。
5.3.2 控制模块参数
由于并不存在“火星文”数据集,本文从互联网中搜集了150 个使用“火星文”的电子商务平台口令链接样本 (包含5672 个字符),我们对这些样本进行了清洗,去除了样本中具有传统平面媒介语言形式的部分,最终获得包含4896 个字符的火星文样本集。我们人工为每个样本生成对应的普通样本(即具有传统语言形式的样本)。通过比对“火星文”样本与其对应的普通样本,经统计发现约53.2%的“火星文”构字方式符合S-TT 模块,同时,在隐写过程中,使用其余汉字处理模块会造成文本膨胀。因此,本文认为简繁体转换模块使用概率应大于其余4 个汉字处理模块。实验过程中发现,字体重构模块算法复杂度较高,对其降低使用频率可减少含密文本生成时间,其余模块的使用概率将参考表 6 生成。本文实验中,为了尽可能增加隐写容量同时满足以上条件,我们设置参数:ε1=0.35,ε2=0.55,ε3=0.65,ε4=0.95。
5.3.3 字体重构模块参数
字体重构模块参数iθ的取值会对信息嵌入成功率造成影响。本文针对已选取的150 个“火星文”样本,从中提取出汉字。统计结果显示,在提取出的汉字中有346 个汉字进行过字体重构,本文对这些汉字进行如下的处理:
Step 1: 计算每个汉字树形结构BT的左子树BTl与右子树BTr高度差的绝对值。
Step 2: 绘制关于汉字左右子树高度差绝对值的直方图。
实验结果如图10 所示,该最小值为0,但考虑到θ1=0会使信息提取算法失效,因此设置θ1=1。在此实验结果上,再次对这346 个汉字进行如下处理:
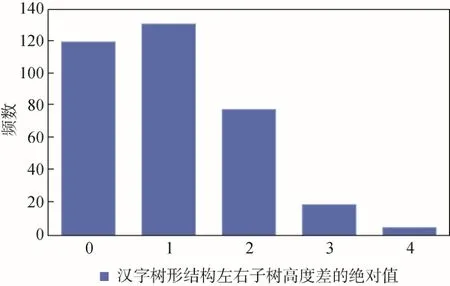
图10 汉字左右子树高度差的绝对值直方图Figure 10 Absolute value histogram of height difference between left and right subtrees of Chinese characters
Step 1: 选取左右子树高度差为0 的汉字并组成新的汉字集合。
Step 2: 在新汉字集上,计算左右子树所组成汉字部件的笔画之差的绝对值并进行直方图统计。实验结果如图11 所示,该最小值为0,但考虑到θ2=0会使信息提取算法失效,因此设置θ2=1 。
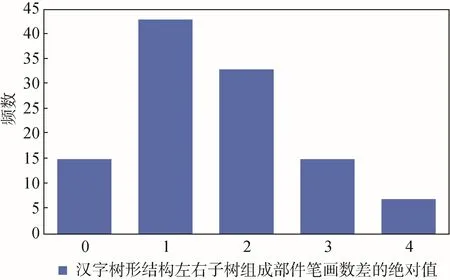
图11 汉字左右子树组成部件笔画差的绝对值直方图Figure 11 Absolute value histogram of stroke number difference between left and right subtrees of Chinese characters
5.4 隐写实验
5.4.1 非文本生成隐藏算法对比分析
本文所提出的隐写方案的嵌入操作依赖于对原始文本的修改,因此仍然属于基于修改的文本隐藏算法。由于文献[34-36]与本文所提出的信息嵌入方案都是对原始文本中文字体进行修改,在算法设计上具有相似性,因此,本文首先对这类算法进行实验。我们从新华网中随机选取了10种新闻类别,并从各个新闻类别中的头条新闻文本中选取了10 条文本,其中每条文本包含200 个字符(不含标点符号)。我们对这100 条文本进行顺序打乱,最终获得了一个涵盖多种新闻类别的文本数据集NewsData。与此同时,相应的100 条随机生成的且长度为400 的二进制串被用以模拟待嵌信息,其中,0 与1 出现的概率都为50%。SSE、ESE 和TBE的各项指标可从理论得出。值得注意的是,ESE 算法的嵌入率ER 和嵌入效率EE 与待嵌信息分段长度L有关,根据文献[36]其隐写性能可由如下公式得出:

对于L ∈N*,易得公式(9)在L=3 时候取最大值。SSE 算法为ESE 的一种特殊情况,即L=1。TBE 算法的隐写性能与模板长度T和选取嵌入字符数O有关,可由如下公式得出:
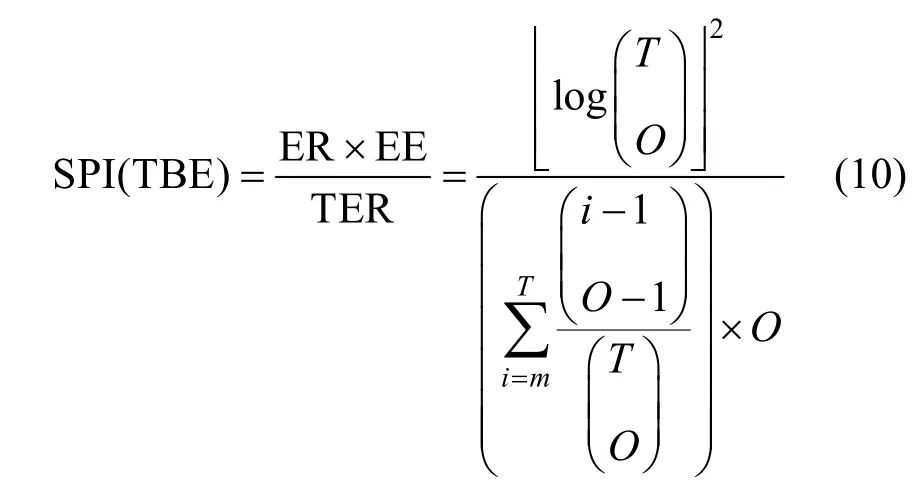
根据文献[36],T∈ {50,100,200}时,当T=200且O=52 时,TBE 算法可以获得最好的隐写性能。由表7 可知,本文所提出的文本信息隐藏模型在隐写性能上优于其他基于字体修改的隐藏方案,且相较于TBE 算法提升了52%。本文模型中文单字符嵌入能力表达式如下:
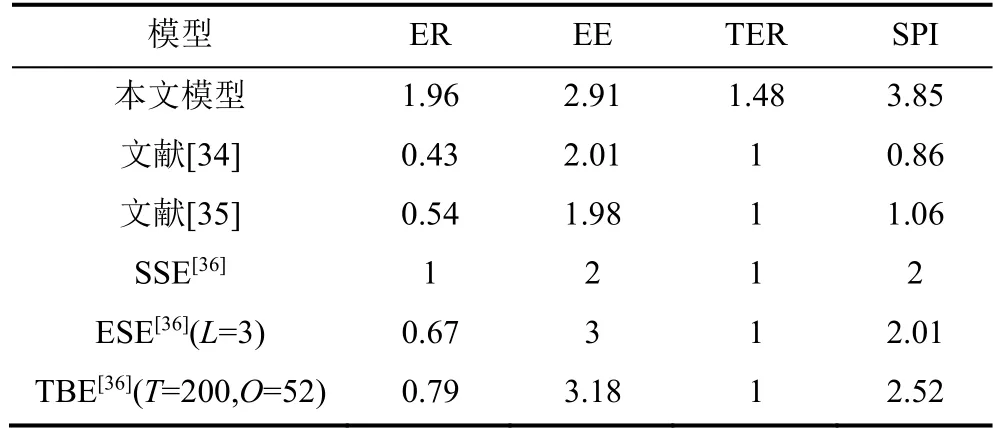
表7 基于字体修改信息隐藏算法实验结果Table 7 Experimental results of information hiding algorithm based on font modification

根据表6 以及参数εi的设置,可得SCEC(Ours)=1.87比特。值得注意的是,文献[34-35]所提出的隐写方案依赖于Word 文本,因此不具有通用性。
除以上基于字体修改的算法外,其他非文本生成隐藏算法也与本文模型进行了对比。本文参考文献[50],给出各个算法的嵌入能力与适用文档类型,如表8 所示。值得注意的是,文献[27]通过修改字符的RGB 值完成单字符3 比特的嵌入,然而这类算法不具有通用性,且正常情况下,Word 文档中大部分字体颜色都相同,对颜色细微的修改虽然能躲避人类视觉的观测却难以躲避机器检测,因此该算法隐蔽性较弱。表8 中,本文模型的嵌入能力依赖于前文所设计各项表,在5.4.2 节中,我们将更加深入分析本文模型的嵌入能力,同时给出提升隐写容量的方案。综上,相较于非文本生成隐藏算法,本文模型在嵌入能力以及通用性方面都具有明显的优势。
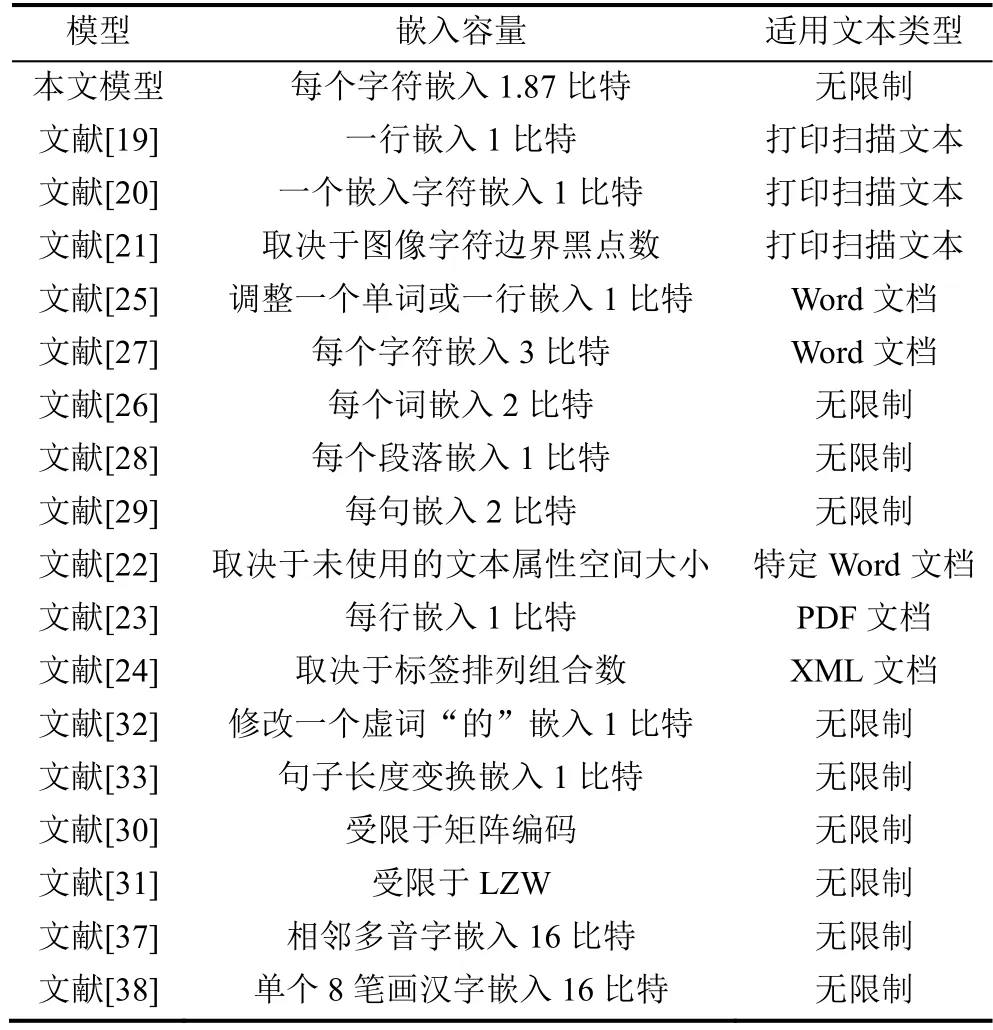
表8 非文本生成隐写算法对比Table 8 Comparison of steganographic algorithms for non-text generation
5.4.2 文本生成隐藏算法对比分析
中文文本生成隐写算法可分为两类: 诗词生成隐写与普通文本生成隐写。在诗词生成隐写领域,相比于其他算法,Qin 等[43]模型所生成的绝句诗具有较好的可读性和较高的嵌入率。在文献[43]中,一首绝句诗的嵌入容量由如下公式得出:

其中,Knum、Pnum、Rnum、beamnum分别表示主题词数、模板类数、韵律类数、候选诗句数。因此,其单字符嵌入能力可由如下公式计算得出:

其中,Np表示绝句诗每行中文字符数,标点符号未纳入考虑范围。文中,给定Pnum=8和Rnum=36且Np∈{ 5,7},因此,SCEC(Qin) 主要由Knum与beamnum决定,beamnum设置过大会影响绝句诗的生成质量,然而,Knum的取值并没有限制,这也是此算法具有较高嵌入率的主要原因。对于本文模型,根据公式(11),在参数εi确定的情况下,其单字符嵌入能力受限于各个隐写子模块。通过分析发现,各个隐写子模块的嵌入能力极度依赖于隐写控制字符表(表2)、相似字符表(表3)和同音字表(表5)。在不修改本文模型算法的情况下,如下方案可提升嵌入能力:
(1) 由于本文只选取了2500 个简体字和与其对应的繁体字,这直接影响了同音字表(见表5)每行元素的数量,从而影响了HS 的嵌入能力,因此可扩充scΩ,增加同音字表中每行中文字符个数,从而提升HS 模块的嵌入能力。
(2) 增加相似字符数,提升C-PT 模块与N-CCS模块的嵌入能力。
(3) 利用网络特殊字符作为隐写控制字符,根据图1(a)与图1(b)所示,网络特殊符号是“火星文”文本的组成成分之一,且这些符号并没有使用限制。可利用特殊符号替换不可见控制字符,增加表2 中每个类别的候选字符数,从而增加隐写控制字符的嵌入容量。
无论是基于诗词生成隐写算法还是基于普通文本生成隐写算法,理论上,本文模型都可以在不修改模型算法的情况下,利用如上三种方式,达到与之接近的嵌入能力。文献[43]所提出的隐写方案在信息提取过程中需要从含密诗中提取主题词、韵律和模板类型,并将这些信息传入至已经训练好的语言模型中生成候选诗句,并利用所生成的候选诗句进行信息提取操作。在面对有损信息传输以及篡改攻击,这些信息,例如主题词,有一定的概率丢失或者被篡改,这将导致整个信息提取过程的失败。同样,对于文献[44-45],通过分析其信息提取算法,第n个字wn的信息提取依赖于由概率p(wn|w1,… ,wn-1)所决定的字候选集,含密文本中任意一个字wi的丢失与篡改都有可能导致p(wn|w1,… ,wn-1)概率的改变,从而可能导致后续提取任务失败。然而,本文隐写子模块的信息嵌入与提取操作都是相互独立的,任意一个模块的提取失败都不会影响到其他模块的信息提取,这也是本文模型相较于文本生成隐写算法的优势。
5.4.3 “淘口令”生成案例
本文以互联网中流行的“淘口令”作为生成案例,将重要信息嵌入至“火星文”文本中,使其不再暴露于外界,这在一定程度上降低了重要信息被检测的风险,有效解决了目前互联网中常见的文本信息拦截问题,保障了信息传递的安全。图12 展示了含密“淘口令”的部分生成样例。其中,字符编码采用UTF-8,图中半部分利用了不可见控制字符,下半部分则利用5.4.2 节所提出的网络特殊符号方案。值得注意的是,图12 中的信息嵌入过程并没有使用完整段原始文本,因此部分含密文本仍旧保留原始字符,可见本文模型具有较好的嵌入能力,同时,这也符合我们日常生活中所看见的淘口令样本。
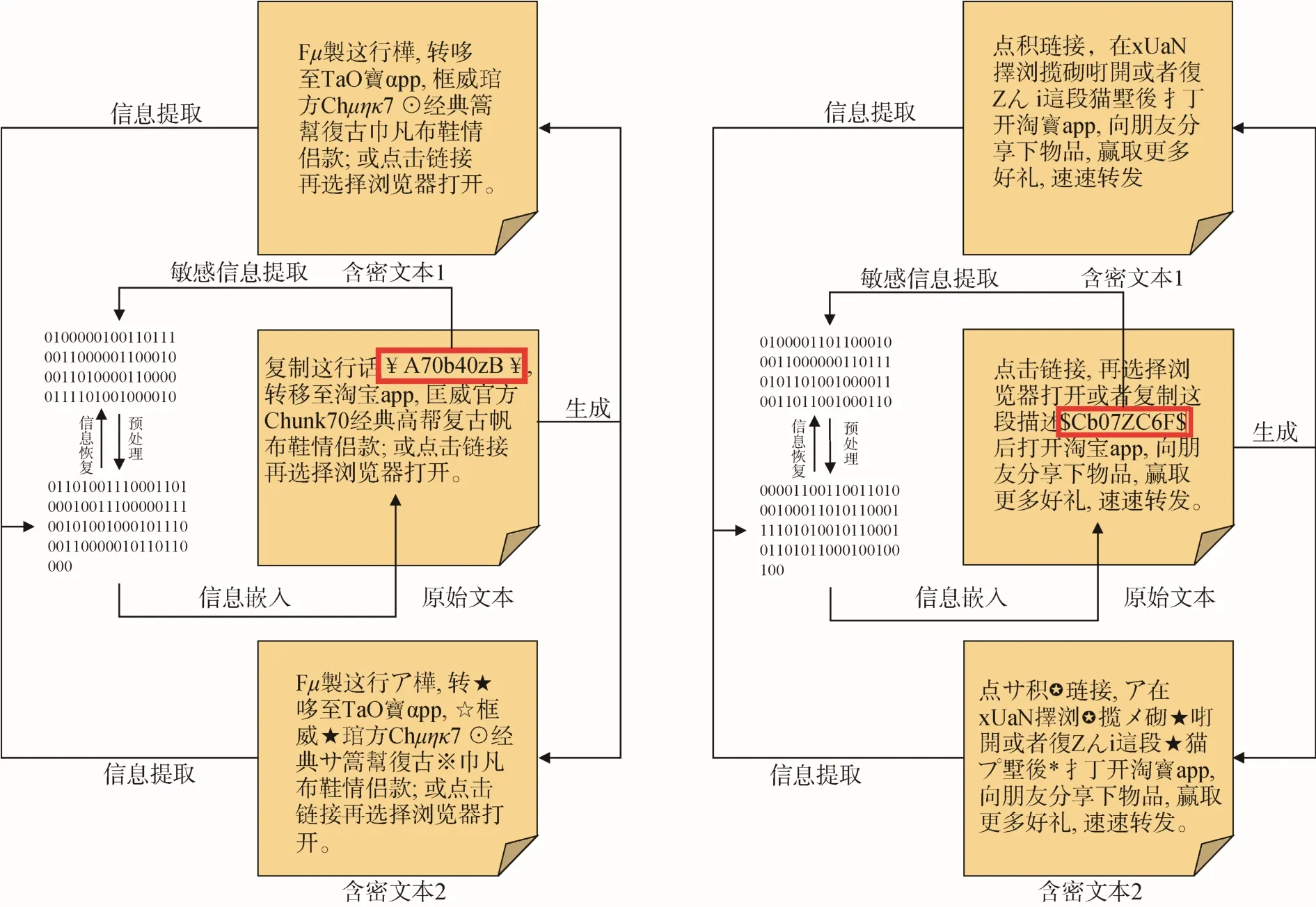
图12 含密“火星文”文本生成案例Figure 12 Generation case of “Martian”text with secret data
5.5 隐写安全性分析
本文隐写方案所生成的“火星文”与网络中的“火星文”并无差别,因此,具有一定的隐蔽性。由于本文隐写载体特殊且所生成的含密“火星文”样本复杂多样,在攻击者不知晓该隐写系统的编码方案以及相关表的情况下,做出准确的隐写分析将具有相当大的难度。传统针对语义[51]、语法[52]以及文本图像的隐写分析技术[53]均不适用于本类文本检测。
然而,本文使用不可见控制字符(见表2)来辅助隐写,这类字符的使用在互联网中非常罕见,倘若隐写分析者仅针对该类字符进行检测,则可以达到100%的检测准确率。所幸5.4.2 节中所提出的第三个嵌入能力提升方案可有效解决这类问题。本文所使用的网络特殊字符部分来自于网站①http://www.360doc.com/content/09/0820/17/180960_5085129.shtml。由于“火星文”本身复杂多样的特性,可见隐写控制字符的选择范围将非常广泛,倘若隐写分析者针对这类特殊字符进行检测,那么可能会将互联网中良性的“火星文”文本或者普通文本误判为隐写文本,这是得不偿失的。倘若分析者试图通过统计的方式发掘这类字符的使用规律,由于本文默认使用的每一类隐写控制字符的字符候选数最多为4(见表2),若观测次数趋于无穷,那么分析者发掘出隐写控制字符的使用模式的概率将会趋于100%,也就是说,分析者必然能知晓这些控制字符的使用规律从而作出隐写分析判断。针对这类隐写分析攻击,本文提出一下两种应对措施:
(1) 适当扩大每一类隐写控制字符的字符候选池。表2 中,每一类隐写控制字符最多只有4 个候选字符,若扩充其候选字符数,可增加统计隐写分析的难度。(2) 不定期更新隐写控制字符表。隐写控制字符表的更新主要是为了尽可能模糊隐写控制字符的使用规律。
此外,“火星文”虽然普遍存在于互联网中,然而其并非为主流的文本语言形式,因此,当通信双方利用“火星文”进行消息传递时,可能会引起第三方的怀疑,因此,本文所提出的文本隐写系统并不适用于对文本语言形式要求非常严格的场景。
5.6 鲁棒性分析
5.6.1 文本拦截攻击
“火星文”字符复杂多样,且呈现方式没有规律性。目前,市场上尚未有成熟的针对“火星文”拦截的信息过滤软件。与此同时,本文直接将重要而又敏感的信息嵌入至文本并生成“火星文”,如此便使得大部分针对内容屏蔽的信息过滤系统失效,从而有效降低了文本因内容被拦截的风险。为了验证其有效性,此小节中,本文随机生成了100 个不同的“口令”信息并利用图13 中左部分的广告文本模式生成了100 个“火星文”文本,最后利用网易易盾所提供的文本检测接口①https://dun.163.com/trial/text进行广告内容检测。图13 可视化地给出了两个原始广告文本以及对应的两个含密文本的检测结果,其中“口令”部分为4 个英文或者数字字符,编码方式为UTF-8 且为随机生成。实验结果显示,该100 个“火星文”文本里有18 个文本的检测结果显示为疑似(广告-商业推广),其余均为通过,其中,这18 个疑似样本中的“淘宝”二字均只进行了简繁体变化。基于以上结果,可以说明本文所提出的文本隐写系统在一定程度上可以规避文本信息拦截。
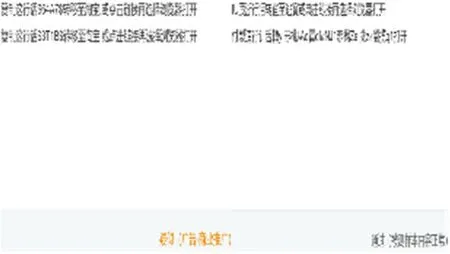
图13 可视化基于不可见隐写控制字符的文本内容检测案例Figure 13 Visualization of a text content detection case based on invisible steganographic control characters
5.6.2 文本篡改攻击
若攻击者进行篡改字符恶意攻击,这便使得信息提取准确率大大降低。为了获得所提出文本隐写系统的抗篡改攻击能力,本文首先随机选取了5 个普通中文文本,其中每个文本含有的字符数大于24。接着,为每一个普通中文文本分配30 个不同的待嵌比特串,其中每一个比特串的长度为32 位。然后,对得到的150 个含密“火星文”文本进行修正,即去除不含密的字符使得“火星文”文本为满嵌状态,此步骤主要是为了保证攻击者只对含密字符进行篡改。最后,我们对这150 个满嵌文本进行1 至6 字符的随机篡改。图14 直观展现了不同篡改等级下150 个含密文本的平均信息提取成功率。可以看出,即使修改了6 个字符,本文所提出的文本隐写系统的平均信息提取成功率仍然能保持在70%以上,因此,可以说明,我们的隐写系统具有一定的抗篡改攻击能力。
然而,图14 也展现出平均信息提取成功率会随着随机篡改次数的增加而近似地线性地下降的现象。为了缓解恶意攻击对该文本隐写系统的影响,本文提出如下三种应对方案:

图14 “火星文”生成隐写系统在不同篡改等级下的平均信息提取成功率Figure 14 Average information extraction success rate of the“Martian”generation steganographic system under different tampering levels
(1) 纠错编码。若将恶意攻击看作信息传输过程中发生的错误,便可利用纠错码提升信息提取的准确率,从而在一定程度上缓解恶意攻击对隐写系统造成的影响。具体的编码方案需考虑实际应用中纠错码的纠错能力、编码效率以及解码能力,因此在纠错码的选择上,本文没有给出具体的方案。
(2) 冗余字符嵌入。在含密文本中,冗余字符不含有秘密信息,然而对于隐写攻击者来说,任何一个字符都有可能是含密载体。因此,当隐写攻击者对文本进行恶意篡改时,该方案在一定程度上能够缓解恶意攻击对信息提取准确率所带来的影响。然而,一味地增加冗余字符也会增加信息传输成本,并且会大幅度加大信息提取步骤的难度。
(3) 单字符嵌入容量控制。当一个字符具有较大的嵌入容量,在面对篡改等恶意攻击时,会使提取信息的准确率大大降低,从而降低文本隐写系统的鲁棒性,因此,本文在设计相关表时,有意减少单字符嵌入容量。
本文提出了一种以“火星文”为载体的文本隐写系统,根据实验结果分析,该隐写系统具有较好的隐写性能,在实际生活中,可有效规避文本信息拦截问题,具有一定的应用价值.据调查,这也是第一个使用网络语言为隐写载体的文本隐写系统。目前本文所提出的文本隐写系统的隐写操作对象只为汉字、英文字符以及阿拉伯数字,在未来的工作中,将会考虑“火星文”中出现的其他字符,设计出更多的隐写模块,同时在参数设置方面,本文将尝试从数值优化角度对隐写参数进行设置,从而进一步提升该文本隐写系统的隐写性能。
猜你喜欢 字符比特火星 玩转火星海外文摘(2021年7期)2021-08-31论高级用字阶段汉字系统选择字符的几个原则汉字汉语研究(2020年2期)2020-08-13火星!火星!大科技·百科新说(2020年10期)2020-03-01字符代表几小学生学习指导(低年级)(2019年12期)2019-12-04一种USB接口字符液晶控制器设计电子制作(2019年19期)2019-11-23图片轻松变身ASCⅡ艺术画电脑爱好者(2019年8期)2019-10-30比特币还能投资吗海峡姐妹(2017年10期)2017-12-19比特币分裂三联生活周刊(2017年33期)2017-08-11比特币一年涨135%重回5530元银行家(2017年1期)2017-02-15神秘的比特币CHIP新电脑(2014年8期)2014-08-13