杜新玉,李宁
(北京信息科技大学 计算机学院,北京 100101)
近年来,知识图谱作为结构化人类知识的一种形式,引起了学术界和工业界的研究关注,被广泛应用于自然语言理解、问答、推荐系统等人工智能任务中[1]。随着学术期刊等的数字化转型,知识图谱在学术文献的知识表示、知识挖掘、知识检索等方面的应用也成为研究热点。但是,早期研究大多数局限于对学术论文的外部特征(如篇名、作者、机构、关键词、期卷、出版商等)、短语、关键术语等知识内容构建知识图谱[2-5]。近年来,学者们开始针对学术论文语义知识(如背景、方法、结果、结论)构建知识图谱,但是其所包含的语义知识不够完整,难以实现复杂的语义检索和问答[6-9]。
学术论文是科研成果的基本载体和传播科技知识的主要媒介,查找和阅读大量的文献是科学研究的关键环节。在文献调研和阅读时,我们可能会想准确快速地获取一些问题的答案,如“有没有文献提到用某方法解决了某问题”,“针对某目标,已有的研究提出过哪些方法,效果如何”,“某方法的最好的实验结果如何”,等等。但是,在海量文献资源下,目前的一些知识服务平台(如知网、万方、百度学术等)仅提供了从篇名、主题、作者、单位、关键词、摘要、参考文献、中图分类号、文献来源等角度的文献检索方式,检索结果反馈的往往是整篇文献或整段文字,仍需检索人员进行筛选,然后仔细阅读筛选出的文档。这显然无法满足科研人员准确且高效地获取知识和信息的需求。若要实现上述的智能问答和检索,就需要构建特定的知识库,该知识库需要包含学术论文中的语义知识,如问题、方法、结果、结论等。但是,学术论文的撰写者通常采用线性方式以自然语言进行表述,无法直接体现论文中的语义知识。因此,本研究主要解决的问题是,如何为学术论文的知识表示定义合适的本体以及如何基于本体构建论文知识图谱。
本体作为一种知识表示的方法,同时可以作为一个知识库的骨架和基础,能够从语义和知识两个层面上对文本信息进行描述,被广泛应用于学术文献的知识表示、知识管理语义检索和科学论证分析等应用中[10]。本文首先根据知识元、本体和知识图谱的原理,结合细分论文内容、关联知识单元、构建知识图谱的目标,通过对学术论文内容的分析,确定知识类型并定义为本体概念,用本体对概念、关系的定义来描述学术论文中所包含的知识单元及其之间关系。然后,基于本体构建结构化的语义知识库(即知识图谱),以期实现面向学术论文的语义检索和智能问答。
1.1 学术知识图谱研究现状
学术知识图谱的构建是目前研究的热点,近期还列入了国家重点研发项目指南。2017年,清华大学和微软研究院[2]联合发布了开放学术图谱(open academic graph,OAG)。该图谱融合了ArnetMiner学术图谱[3]中1.55亿篇学术论文和微软学术图谱(Microsoft academic graph,MAG)[4]中1.6亿篇论文的元数据。数据类型包括论文中的题目、作者、会议、年份、摘要等。随后,2019年发布了OAG2.0版本,该版本增加了论文、作者、出版地点这3类实体及相应的匹配关系。OAG集成了大量的论文元数据信息,通过数据共享,提供智能化服务,推动了学术知识图谱的发展进程。Bratsas等[5]通过语义注释和链接学术研究领域来构建科学知识图谱,将各个科学领域的所有研究领域包含在一个共同的层次结构中。上述研究对提高文献的检索效率具有重要的价值。近年来,针对学术论文的知识图谱研究从论文元数据深入到了论文中深层的语义知识。Auer[6]等提出开放研究知识图谱(the open research knowledge graph,ORKG),允许以结构化和语义的方式描述传统科技论文中描述的研究贡献,通过 DOI 从 CrossRef 检索文章的关键元数据,然后使用专门的输入字段描述论文的内容,将论文添加到 ORKG。描述内容包括所解决的研究问题、使用的材料和方法,以及所取得的成果,以使研究贡献与解决同一研究问题的其他文章具有可比性。Fathalla等[7]提出一种用于描述综述文献内容的SemSur本体,包含研究问题、方法、实现、评估4个核心概念,基于该本体生成综述知识图谱。曹树金等[8]通过抽取论文中的创新句进行实体识别来挖掘创新内容,构建面向学术论文创新内容的知识图谱。Roa等[9]为与深度学习算法和方法相关的论文创建一个深度知识图谱存储库,以帮助改进学术领域中相关信息的搜索和检索。
从上述研究不难发现,已有学术知识图谱研究局限于论文的外部特征和著录信息,只有少数学者针对学术论文的内在语义知识进行了图谱构建的研究,即使这样,这些图谱所包含的语义知识尚不够全面,无法应对针对学术论文的复杂的语义检索和问答。
1.2 学术论文知识表示研究现状
学术论文中通常包括对研究背景、研究方法、研究结果及结论等信息的论述。许多学者针对文献的知识内容从不同的视角进行分析,提出了不同的本体和模型。
Groza等[11]提出了用于文档语义标注的框架(semantically annotated LaTex,SALT)。SALT框架较早用于文献修辞单元的标引,包含了文档本体、修辞本体和标注本体,其修辞本体在ABCDE模型[12]基础上进行了扩充,包括摘要、动机、贡献、评估、讨论、背景、结论等概念;
还定义了对立、环境、让步等11种修辞关系。SALT本体虽然组件粒度定义较粗,不能细致地描述学术论文各个部分的内容信息,但是其分类体系和关系定义为相关研究提供了借鉴。Liakata等[13]提出一种能够反映科学研究的结构和知识类型的核心科学概念(core scientific concepts,CoreSCs);
万维互联网联盟(World Wide Web Consortium,W3C)[14]在2011年发布的科学篇章修辞块本体(ontology of rhetorical blocks,ORB),旨在为科学出版物创建一个普适的修辞模块粗粒度集合,针对其文档内容和形式提供细粒度语义入口;
Iorio等[15]构建模式本体(the pattern ontology,PO)关注句子、段落、章节等结构组件的属性描述;
Ribaupierre等[16]提出一种以用户为核心的科技文献标注模型SciAnnotDoc。但是,这些研究对学术论文内容的语义描述不够细致全面,粒度较粗。因此,大多数学者进一步在细粒度层面构建用于学术论文内容语义描述的本体。Shotton等[17]提出的篇章元素本体(discourse elements ontology,DEO)借鉴SALT框架中修辞本体的部分修辞结构元素,定义了背景、结论、数据等具有不同修辞功能的组件,为文档中的修辞元素提供了结构化词汇表。DEO能够较为细致地描述论文中的修辞单元,但缺少单元之间的关系定义。文档结构本体(the document components ontology,DoCO)[18-19]提供了结构化词汇表,定义了题名、摘要、章节、句子、段落等文档组件。但是,DoCO仅对论文的篇章结构进行细粒度的描述。秦春秀等[20]提出了一种面向科技文献知识表示的知识元本体模型,对学术论文的内容进行了分层表示,同时定义了同位关系和等级关系。该模型对科技文献内外部特征进行了细粒度描述,对科技文献的深层次知识服务起到了较大的作用。王晓光等[21]在Zhang Lei等[22]的研究工作基础上,构建了包含12个一级类、28个二级类的科学论文功能单元本体(functional units ontology,FUO)。该本体模型从内容组件的语义功能角度对科学论文的组织结构进行细粒度建模,更细致地描述了科学论文的内容组成要素,更好地揭示了科学论文功能单元的语义功能,对学术论文内容的语义描述具有积极意义。但是,该模型没有考虑功能单元之间的关系定义,无法表示各个功能之间的逻辑关系。孙建军等[23]在继承现有标注本体(如DEO[17]、DoCO[18]、C4O[24]、FaBiO和CiTO[25]等)的基础上构建了学术文献语义标注本体。虽然,该标注本体涉及了学术文献的种类、科学论述、结构元素、参考文献等多种内容,但是不能全面、细致地描述学术文献的内容语义。牛丽慧等[26]在探索科学论文的语义标注模式时,提出了一个语义标注框架,实现了论文物理结构和论证结构的语义标注功能。其中,标注本体采用篇章修辞块本体ORB[14]、科学实验本体[27]、微出版物本体[28]、纳米出版物本体[29]等。尽管这些学者提出的标注框架涵盖了科学论文的物理结构和论证结构,但这些框架中缺失了论文中一些基本的语义单元,如:研究背景、研究问题和未来工作等。
此外,有些学者从科学论证的角度提出不同的模型或本体,对文章内容进行划分。如,Teufel[30]提出了用来分析科技论文论证结构和修辞结构的论证块模型(argumentative zoning,AZ)。由于AZ模型的标注实验局限于计算机语言学领域,因此,Teufel等[31]在AZ基础上进行了扩展更新,建立了论证块II模型(argumentative zoning II,AZ-II)。Soldatova等[27]提出科学实验本体(ontology of scientific experiments,EXPO)。Vitali等[32]基于图尔敏论证模型提出论证模型本体(argument model ontology,AMO)。王晓光等[33]提出科学论文论证本体(scientific paper argumentation ontology,SAO),用于揭示科学论文的重要观点、结论及其论证过程。曲佳彬等[34]构建了句子级及实体级科学论文论证结构本体。科学论证是学术论文中极为重要的过程。虽然,上述论证模型或论证本体只考虑了科学论证的必要元素,无法对文章内容作出细致全面的描述,但是对学术论文内容语义描述仍具有很好的参考价值。
目前针对文献内容进行语义描述的研究存在以下不足:1)仅简单地使用方法、结果、结论等修辞元素对文献内容进行粗粒度语义描述,难以细致全面地揭示文献中的语义单元;
2)未定义语义单元间的关系,或定义过于简单,无法反映学术论文语义单元之间的逻辑关系。
针对上述不足,本文在已有成果的基础上,构建学术论文表述本体(academic paper expression ontology,APEO),以期能够细致全面地表达学术论文中的语义单元,为学术论文知识图谱的构建提供基础,进而实现学术资源的语义检索和智能问答。
2.1 本体的设计目标
本文基于已有的文献内容表示本体和模型,通过对学术论文内容的语义标注和分析,构建学术论文表述本体APEO,以期细致全面地表达学术论文中的语义单元及其之间的逻辑关系。APEO的概念模型如图1所示。为了直观简洁地展示本体概念模型,图中仅包含一级类。该本体涵盖了29种语义单元类型,18种逻辑关系,全面地表征了学术论文中的语义单元,细致定义了语义单元之间的逻辑关系。

图1 学术论文表述本体的概念模型
2.2 本体中的类设计
本文首先参考FUO,依据FUO中定义的类创建编码节点,建立编码体系,以对学术论文内容进行语义标注和分析。在标注过程中根据学术论文表述的语义内容不断扩展调整编码节点,更新编码体系,最终确定学术论文表述本体的层次概念类。如表1所列,包括背景、研究目标、研究意义、研究内容、方法、实验、结果、结论等17个一级类,以及对一级类进行进一步细分得到的29个二级类。

表1 学术论文表述本体的层次概念类设计
2.3 本体中的属性设计
表1确定了本体中的类及类的层次关系,除此之外,还需要进一步描述这些类的内部结构,才能完整地表达论文的语义单元及其逻辑关系。这些类的结构信息就是类的属性。本文设计了类的外部属性和内部属性。其中,外部属性用于描述本体中的类(论文中语义单元)之间的关系,内部属性则描述自身的属性信息。
2.3.1 外部属性设计
为了准确地描述上述各个语义单元之间的逻辑关系,本文借鉴论证结构中的论证关系[33]、修辞结构中的修辞关系[35]、语篇分析中的篇章关系[36]以及知识元关系等,加上自定义关系,共定义18种逻辑关系。这18种逻辑关系即为学术论文本体中的外部属性集,具体内容如表2所示。

表2 学术论文表述本体的外部属性集
2.3.2 内部属性设计
本体中的类有一些基本的内部属性,如信息的描述、所属的文章、标签信息等。此外,在学术论文中,作者通常会引述、参考一些他人成果,因此,学术论文表述本体中的一些类(如背景、已有研究、本文方法等)具有来源信息;
再有,作者会持有一定的态度或观点,因此,学术论文表述本体中的一些类(如研究意义、研究缺陷、结果、结论等)往往带有一定的情感信息。本文定义了5种内部属性,具体内容如表3所示。

表3 学术论文表述本体的内部属性集
为了对APEO进行评估,本研究借助Nvivo数据分析工具[37],采用“演绎式”编码。首先,根据本体中的类创建编码节点,建立编码体系;
然后,使用该体系对样本资料进行编码;
最后,存储并分析标注结果。本研究在标注之前对PDF格式的论文样本进行了预处理,将其转成Microsoft Word使用的DOCX格式,并且去除了图表、公式、英文摘要及参考文献。具体标注流程如图2所示。

图2 学术论文语义标注流程
3.1 标注样本的选择
因为特定领域的文章有利于分析和比较结果,笔者根据以往相关研究[20-21,30],选择其中最大值来确定标注样本的数量。我们从《计算机科学》期刊随机抽取了2017-2021年间发表的40篇研究论文作为标注样本。该期刊论文格式规范,质量较高,篇幅合理,较适合用于学术论文的标注实验。
3.2 标注实验及编码一致性分析
本研究采用的是人工标注方式,需要标注人员对学术论文内容进行判断和理解。因此,为了确保标注的可靠性,在进行语义标注实验之前,从40篇论文样本中随机选取了8篇进行一致性检验(即编码一致性分析)。首先,笔者对这8篇论文进行标注;
在标注结束后,由一名最熟悉编码规范的人员再次对这8篇论文进行标注;
然后,计算Kappa系数。Kappa系数是用于一致性检验的指标,亦可用于衡量分类效果的好坏[38]。大部分类目的结果在0.6~1之间,具备实质一致性。而后,笔者对剩余32篇论文进行了标注,最终完成其标注工作。
3.3 标注结果分析
本文使用本体覆盖率来评估APEO在所有论文中的覆盖情况;
使用文本编码覆盖率评估APEO对单篇论文的覆盖能力。即从两个方面验证APEO对学术论文语义单元及其逻辑关系的表示能力。
3.3.1 本体覆盖率
本体覆盖率是指含有本体类目的文章数在总文章数中所占的比例。即统计单个编码节点的编码项数,结果如图3所示。
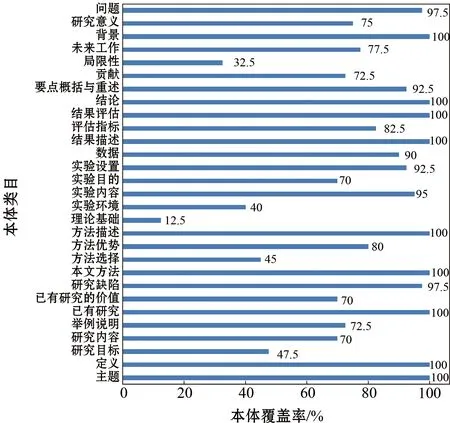
图3 APEO的本体覆盖率统计
从图3可以看出,在40篇论文中,不同类目出现的频率不同。其中,“背景”、“结论”、“结果评估”、“方法描述”、“已有研究”等9个类目覆盖了所有学术论文,因此这些类目可以视为常见类目,也说明了这部分类目的重要性。此外,除“理论基础”、“局限性”、“实验环境”、“方法选择”、“研究目标”之外,其余类目覆盖率都在70%以上,说明了APEO中的大部分类目具有代表性。
3.3.2 文本编码覆盖率
单个节点编码的长度在资料内容中所占的比重称为节点的编码覆盖率。通过对单篇论文中所有类目在文中的编码覆盖率进行求和,可以得到整篇论文的文本编码覆盖率,以此评估APEO是否能够覆盖各篇学术论文。统计结果如图4所示。

图4 APEO的文本编码覆盖率统计
从图4可以看到,文本编码覆盖率最小值为75.33%,最大为92.57%,大部分落在80.00%到90.00%区间内。40篇论文的平均文本编码覆盖率达到84.64%。因此,可以说明APEO中的类目能够表达各学术论文的大部分内容。这里需要说明的是,为简化处理,标注前对论文部分内容进行了适当删减(如图、表、公式等),标注时对一些内容未做标注(如关键词、各级标题等),因而文本覆盖率在统计结果上并不十分准确,但应该优于图中的结果。
3.3.3 与其他本体比较
为了对比APEO的表示能力,本文使用目前较为成熟的FUO和DEO对相同的40篇样本论文进行了标注,结果见表4。由表4可以看出,本文提出的学术论文表述本体APEO的本体覆盖率比FUO高出27.78%,比DEO高出17.52%;
文本编码覆盖率比FUO高出16.19%,比DEO高出21.39%。

表4 基于不同本体的标注结果
上述结果表明,相较于已有本体,APEO对于学术论文的语义单元具有较强的表示能力。
知识图谱由数据层和模式层构成。模式层是知识图谱的概念模型和逻辑基础,对数据层进行规范约束。一般采用本体作为知识图谱的模式层,来约束知识图谱的数据层,本质上可将知识图谱视为实例化了的本体。知识图谱的数据层是本体的实例,以“实体-关系-实体”或“实体-属性-属性值”的三元组形式存储,形成一个图状知识库。本文则使用APEO作为模式层,将学术论文中的语义知识单元作为数据层,以此构建学术论文知识图谱(academic paper knowledge graph,APKG)。
4.1 基于APEO的学术论文知识图谱构建
实例抽取是知识图谱构建的重要环节。本研究首先采用自然语言处理工具GATE(general architecture for text engineering)[39]作为标注工具,对来自于《计算机科学》期刊题目为“基于改进自编码器的文本分类算法”和“基于Word2Vec和改进注意力机制AlexNet-2的文本分类方法”的两篇学术论文进行语义标注,得到XML格式的文档;然后,对XML进行解析,得到一系列带有语义标签的实例数据;最后,将得到的实例数据映射到本体层的概念中,并采用Neo4j图数据库进行存储和可视化。学术论文知识图谱可视化结果如图5所示。

图5 学术论文知识图谱示例
4.2 学术论文知识图谱应用探索
本研究针对学术论文内容所构建的知识图谱仅是一个雏形,未来将通过自然语言处理、机器学习等智能化手段实现当前流程中的人工处理环节;
同时,也将考虑实现多篇论文之间的知识图谱融合。在此基础上,对知识图谱的应用进行多方向探索和实现。
学术论文知识图谱和语义技术提供了关于论文中知识单元的分类、属性和关系的描述,这样搜索引擎就可以直接对知识进行搜索。如:可以直接查询某篇论文中的“研究目标”、“背景”、“研究意义”、“贡献”等。如图6所示,本研究基于APKG做了一个初步的语义检索示例。语义检索的实现不仅可以使科研人员高效地获取信息,同时,还可以为智能问答、决策支持、个性化推荐等智能化服务提供支持。

图6 基于APKG的语义检索应用示例
根据问题自动选择或生成相应回复,可以提高信息处理的自动性和资源获取效率,节约人力资源和成本。基于本文提出的知识图谱,可以实现科学研究中的一些智能问答。如“有没有文献提到用某方法解决了某问题”,图7为本研究基于APKG实现上述问答的示例。实现这一智能问答的主要过程是:首先,通过先进的自然语言处理技术对问题句进行解析,得到其中的语义信息,将其转化为结构化形式的查询语句;
然后,从知识图谱中检索相关知识;
最后,给出相关答案。科研人员无需再费时耗力地查阅文献,可以通过智能问答系统快速获取当前研究的相关信息,加快科研进程。

图7 基于APKG的智能问答应用示例
本研究根据知识元理论、本体论及知识图谱理论,在详细分析学术论文内容的基础上,构建了学术论文表述本体APEO,弥补了已有研究中存在的建模粒度过粗、逻辑关系表示能力不足等问题。本文的语义标注实验,也说明APEO能够较为全面、深入地表达学术论文中的语义单元及其逻辑关系,验证了APEO对学术论文知识的表示能力。其次,基于APEO,进行论文内容的语义分析,借助GATE文本标注工具、XML解析工具及Neo4j图数据库初步构建了学术论文的知识图谱。最后,基于APKG,进一步实现了面向学术知识的语义检索和智能问答。
然而,目前的研究还存在一些局限。例如:1)APEO仅对文本内容进行语义化描述,没有考虑论文中其他形式的内容;
2)知识图谱构建过程依赖于人工的分析和处理。针对第一个问题,可以考虑对文本格式外的内容设计专门的语义化描述模型,将论文外部特征、内部特征及图表、公式等多种信息的本体或模型结合,构建多模态知识图谱,从广度和深度两个层面上覆盖学术知识。针对第二个问题,考虑利用自然语言处理技术、机器学习技术进行知识抽取和知识融合,提高知识图谱自动构建的程度,为实现面向学术知识和信息的语义检索、智能问答、智能推荐和自动综述生成等智能化服务提供支持。