袁文勇,李秀广,2*,李瑞峰,易铮阁,杨晓元,3
(1.武警工程大学 密码工程学院,西安 710086;
2.综合业务网理论及关键技术国家重点实验室(西安电子科技大学),西安 710071;
3.网络与信息安全武警部队重点实验室,西安 710086)
随着计算能力的发展,用户需要掌握的数据越来越多,为了节省存储空间和管理成本,用户往往把数据外包到云服务器[1]。由于用户外包数据后通常会删除本地数据以释放空间,数据保留在云中,用户失去对数据的直接控制,导致云存储出现各种安全问题[2]。数据的完整性就是其中的重点研究问题之一。
为保证数据的完整性,多种审计方案被提出。早期方案[3-4]都是采用绝对性检测,用户需要重新下载所需检测的数据,再与本地数据进行对比,实现完整性验证的目的。频繁下载数据来检查完整性对用户来说成本是昂贵且不合理的。2007 年Ateniese 等[5]提出数据持有性证明(Provable Data Posssession,PDP)方案,开创性提出抽样检测的方法验证数据完整性,用户检测数据完整性无需下载数据即可完成验证,减轻了用户计算开销。2008 年Ateniese 等[6]提出可扩展的PDP 方案,实现对数据的部分动态操作。以上方案由用户承担大部分验证开销,用户实际计算能力有限并缺乏专业性。为了解决上述矛盾,2009 年Wang 等[7]提出一种基于第三方审计机构(Third Party Auditor,TPA)的审计模型,TPA 具有专业的计算能力且被行业承认。用户授权TPA 对外包数据进行审计并代表用户完成云中数据的完整性验证。但TPA 不能保证完全可信,有可能窥探用户隐私。为了在审计过程中保护用户数据隐私,Wang 等[8]在审计过程加入随机掩码技术,对参与审计的数据块聚合进行盲化,保证TPA 无法通过对相同数据进行验证从而获取用户数据。随着TPA模型推广,如何保证TPA 如实完成审计请求成为云审计安全的重要问题之一。2017 年张键红等[9]设计出一种新的审计方案,对数据和数据标签进行双重验证,以加强对TPA 的控制并提高用户的审计能力。2019 年Xue 等[10]利用区块链技术提出了一种抵抗恶意TPA 的完整性审计方案,方案有效抵抗了TPA 可能的欺骗行为,并保证了审计结果的正确性,但区块链数据存储成本高昂[11]。Qian 等[12]利用伪随机比特生成器随机生成挑战信息,使TPA 必须每次执行用户的审计请求,避免了TPA 跳过审计直接返回结果的欺骗行为。以上方案均是基于双线性映射的思想,生成标签和验证过程繁琐,对云和TPA 计算能力要求高。
为提高计算效率,防止TPA 欺骗行为和保护数据隐私,本文基于离散对数假设构建新的标签生成算法,利用伪随机比特生成器保证挑战信息的随机性,增加用户和TPA 审计结果的交互过程,检查数据完整性,保证审计结果的可信。计算过程无双线性映射参与,能有效提高计算效率。
1.1 离散对数问题
G是一个阶为大素数q的乘法循环群,其中g是循环群的生成元。已知g和ga,求a的值是困难的,这称为离散对数问题(Discrete Logirathm Problem,DLP)[13]。
1.2 单向散列函数
密码学哈希函数又被称为单向散列函数,它可以将任意长度的消息转化为固定长度的哈希值。单向散列函数具有单向性和抗碰撞性。
1)单向性:由一个输入求得散列值是容易的,由散列值求输入是困难的。
2)弱抗碰撞性:要找到和某条消息具有相同散列值的另一条消息是非常困难的。
3)强碰撞性:要找到散列值相同的两条不同消息是非常困难的[14]。
1.3 伪随机比特生成器
Zhang 等[15]提出比特币新区块生成可被看成是基于时间的伪随机资源,对伪随机比特生成器的定义:

函数的输入是过去或者当前时间t,在比特币系统中容易计算出;
如果是未来的时间,函数的输出是不可预测的。本文方案输入审计的当前时间,利用式(1)计算挑战信息。假设挑 战的数 据块数目为n,则只需 用{θ‖0,θ‖1,…,θ‖(n-1) }分别作为一个映射到数据块集合中的哈希函数的输入,得到的输出便是要挑战的数据块索引集合[15]。
2.1 审计模型
本文可信审计模型有3 个参与方:用户、云服务器(Cloud Server Provider,CSP)和第三方审计机构(TPA)。
用户 上传数据和数据标签到云服务器,委托云对数据进行保管。
CSP 接收用户数据和对应标签,对用户数据进行存储管理,节省用户存储空间和计算资源。云服务器不会恶意对外泄露用户数据信息,否则用户利用云进行存储管理数据将失去意义。
TPA 接收用户的审计请求,对云中用户数据进行完整性验证,并将结果返回给用户。本文模型相较于传统TPA 审计模型增加了TPA 生成的挑战信息与用户的交互,把传统的TPA 直接返回审计结果变成结果对比,具体模型如图1所示。

图1 可信审计模型Fig.1 Model of trusted audit
①用户将数据和数据块标签上传至CSP。
②用户向TPA 发送检验数据完整性的请求。
③TPA 利用伪随机比特生成器生成挑战信息,将挑战分别发送给用户和云服务器。
④CSP 接收挑战后,生成数据完整的证明给TPA。
⑤TPA 接收证明,通过计算返回一个审计值给用户,用户通过检查计算结果判断数据是否完整以及TPA 是否如实完成审计请求。
可信审计模型包括以下多项式算法。
Setup:系统初始化,选取合适的群和哈希函数作为系统参数,并公开。
KeyGen(s) →(pk,sk):选取合适参数生成用户密钥对。
TagGen(M,sk) →(M,K):用户对数据分块后使用签名算法对数据进行签名,将数据M和标签K发送给CSP 后,删除本地数据。
ChallengeGen(t) →C:审计者利用当前时间t和用户的公钥pk,执行ChallengeGen 算法产生挑战C,发送给CSP。
ProofGen(C,M,pk,K) →P:CSP 输入挑战C,数据M、标签K和用户的公钥pk,输出证据响应P,发送给TPA。
VerifyProof(C,P,pk) →W1:审计者输入挑战C,用户公钥pk,生成计算结果W1并发送给用户,用户对比计算结果判断数据完整性。
2.2 设计目标
针对TPA 存在的恶意行为,本文构建了一种无双线线对的可信云审计方案。利用伪随机比特生成器生成随机挑战,保证挑战时效性。增加TPA 发送计算结果给用户验证,由用户判断数据完整性。设计方案可满足以下目标:
1)存储正确性。只有CSP 完整存储用户的文件的情况下,才能通过审计方案的验证。
2)可信审计。方案能够发现TPA 的恶意行为
3)隐私保护。TPA 在审计过程中无法获取用户数据。
4)安全性。方案可以抵抗来自CSP 的伪造攻击和代替攻击。
5)批量审计。实现多个数据的批量验证,无需进行多次单项审计。
6)高效性。方案的审计过程中不需进行双线性对运算,节省计算开销。
3.1 系统建立阶段
Setup:选取阶为大素数q的乘法循环群G1,令g为群G1生成元,Q是群上 的一个 随机元 素,H1:{0,1}*→Ζq,H2:{0,1}*×G→Ζq是两个 哈希函 数。公开系 统参数{G,g,Q,q,H1,H2}。
KeyGen(s) →(pk,sk):用户选取随机数计算用户私钥和公钥。其中{pk,sk}={S,gs},S∈。
TagGen(M,sk) →(M,K):用户对数据文件M分块,表示为:M={m1,m2,…,mn}。完成分块后利用密钥进行签名。对每个数据块mi具体签名过程如下。
用户选取随机数λi,计算:
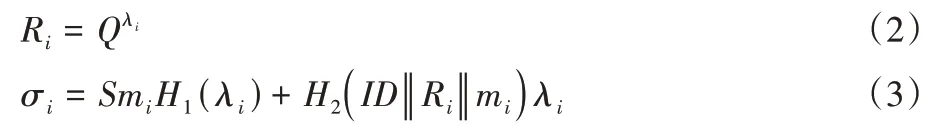
其中:ID为用户身份;
{σi,Ri,H1(λi)}作为数据块mi的标签,将{mi,σi,Ri,H1(λi)}上传到云服务器并删除本地数据。
3.2 挑战阶段
ChallengeGen(t) →C:TPA 接收用户审计请求生成挑战信息。TPA 利用式(1)输入当前时间t,生成θ,计算ρ=H1(θ),从集合{1,2,…,n}选取非空子集I,生成挑战C={ρ,I}发送给云服务器和用户。
3.3 证据生成阶段
ProofGen(C,M,pk,K) →P:云服务 器接收挑战C={ρ,I}。计算:


最后把P={σ,u}发送给审计者。
3.4 验证阶段
VerifyProof(C,P,pk) →W1:TPA 输入挑战C、证据P和用户公钥pk,计算审计值W1。

TPA 把W1发送给用户,用户计算

用户接收到挑战信息,计算vi和云服务器利用式(4)计算过程一致。用户对式(9)进行验证:

如果式(9)成立,证明数据保存完整,TPA 如实完成审计请求。
4.1 方案正确性
如果云服务器完整存储用户数据,则能够通过如下证明:

通过以上数学证明可知,如果用户正确存储数据且TPA如实执行审计请求,则能够通过证明;
否则数据不完整或者TPA 没有如实进行审计。
4.2 抗代替攻击
如果生成证据阶段云服务器利用完好的数据块代替损坏的数据块进行证据生成,那么生成的证明无法通过式(9)验证。
证明 假设数据块和标签{mj,σj,Rj,H1(λj) }已经损坏,CS 利用完好的数据块和标签{mj,σj,Rj,H1(λj) }去代替进行证据生成,CS 进行如下计算:
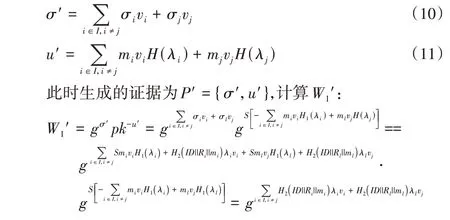
用户计算的W2是根据挑战计算的,不会因为证据而改变。要通过完整性验证,则需要:

4.3 抗伪造攻击
如果离散对数成立,则云服务器无法为不完整数据伪造证据通过完整性验证。
证明 利用文献[16]的安全模型,假设云服务器能够为不完整数据伪造证据通过完整性验证,则说明能够解决离散对数问题。证明过程如下:

其中:分母r2Δu不为0,r2不为0,r2是在随机数上选取的,不为0 的概率为1/q,得到解决DL 问题的概率为1 -1/q,q为大素数,1 -1/q大小不可忽略。如果云服务器能够利用不完整数据伪造证据通过验证,则云服务器能够以不可忽略的概率1 -1/q解决DL 问题,这与DL 假设相矛盾。
4.4 隐私保护
4.5 检验TPA恶意行为
证明 1)抵抗TPA 生成不随机的挑战信息。本文方案利用伪随机比特生成器生成挑战信息,规定TPA 输入当前的审计时间,因此每次得到的式(1)结果都是不一样的;
再利用函数输出结果生成挑战信息,保证了挑战信息的随机性。文献[17-18]是TPA 进行随机数挑选,人为机构无法保证挑战信息的随机性。本文方案中,如果TPA 重复使用之前的挑战信息,由于TPA 要发送挑战信息给用户,用户通过对比之前接收的挑战,很容易识别TPA 这种恶意行为。
2)抵抗TPA 跳过审计直接返回结果的恶意行为。在文献[17-18]中,TPA 直接返回“0”或者“1”说明数据的完整性情况。有可能存在恶意TPA 为了节省开销,直接返回之前的审计结果给用户,不进行审计计算。本文方案通过比较TPA计算的和用户计算的,由用户进行判别审计结果,避免了TPA 跳过审计直接返回结果的恶意行为。
通过以上对TPA 行为的判定,说明本文方案的审计结果是可信的。
实际使用的云环境中存在大量用户和海量数据,TPA 往往需要一次性检查多个用户数据的完整性。在支持单项数据审计的方案基础上,扩展为满足多用户数据的审计方案,实现对多用户云环境的数据审计要求。设参与验证的用户的数量为L,用户l(1 ≤l≤L)拥有文件Ml,满足多用户多数据的具体审计算法如下。
setup:系统参数设置与单项审计方案一致。

{σl,i,Rl,i,H1(λl,i)}作为数据块的标签K。将标签上传到云服务器,并删除本地数据ml,i,其中IDl为用户l身份。
ChallengeGen(t) →C:挑战生成过程与单项审计方案相同。
ProofGen(C,Ml) →P:云服务 器接收挑战C={ρ,I},计算:

最后把证据P={σ,u}发送给审计者。
VerifyProof(C,P,pk) →W1:TPA 输入挑战C、证据P和用户l公钥pkl(1 ≤l≤L),计算审计值W1。

TPA 把W1发送给用户l,用户l计算

用户接收到挑战信息,计算vi和云服务器利用式(4)计算过程一致。用户对W1=W2进行验证,如果等式成立,证明审计的多项数据保存完整,且TPA 如实完成审计请求。
对扩展方案的正确性进行证明:

批量审计方案是基于单项审计方案扩展而来,满足检验数据完整性、抗代替攻击、伪造攻击和数据隐私保护。证明方法与单项审计方案相同。
本文方案的计算开销主要在用户生成标签阶段、挑战生成阶段和验证阶段。在证据生成阶段中,不涉及群元素和哈希函数的计算,故计算开销可以忽略。下面主要对单项审计方案性能进行分析。
定义H为一次单向哈希函数的计算代价,M为在群G1上做一次乘法运算的代价,E为在群G1上做一次指数运算的代价,P为一次双线性对运算的代价,n为文件中数据块的数量,c为查询数据块的数量。|G1|为群G1中元素比特长度,|n|为[1,n]中元素的比特长度,|P|为Zq中元素比特长度。
6.1 计算代价
TagGen(M,sk) →K:生成一个标签主要有一次计算群元素Ri的幂运算和计算σi的两次哈希运算。文件M分为n块,故生成标签计算开销为nE+2nH。
ChallengeGen(t) →C:挑战阶段开销主要计算ρ,故挑战阶段计算开销为H。
VerifyProof(C,P,pk) →W1:验证阶段开销为TPA 计算W1和用户计算W2。计算W1为两次群幂运算和一次群乘法运算;
计算W2为一次群幂运算和c-1 次群乘法运算,故验证阶段计算开销为3E+cM。
主要对比传统存在双线性对云审计文献[8]、无双线性对的云审计文献[17]以及基于Merkle 哈希树的无双线性对(Merkle-Hash-Tree based Without Bilinear PAiring,MHT-WiBPA)审计方案[18]。为了便于比较,统一计算标签数量为n,查询数据块为c。由于单次哈希运算开销很小,忽略本文方案中在挑战阶段的一次哈希运算开销。具体对比情况如表1 所示。

表1 计算开销对比Tab.1 Comparison of computational cost
6.2 通信代价
本文方案通信开销集中在发送挑战和返回证据两个阶段。发送挑战C={ρ,I}过程,审计者可以直接发送一个时间给CSP 即可,由CSP 通过伪随机比特器计算挑战信息,只需将C={ρ,I}发送至用户,通信量为c|P|+|n|;
返回证据P={σ,u}通信量为2|P|。故本文方案总通信开销为(c+2)|P|+|n|。为使结果更加直观,设置 |G1|=|P|=160 bit,|n|=32 bit。具体对比上述文献[8,17-18]情况如表2 所示。

表2 通信开销对比Tab.2 Comparison of communication cost
6.3 实验对比
实验使用Java 语言和利用JPBC 库实现。运行平台是2.5 GHz,i5CPU,Windows 10 操作系统64 位,8 GB 内存。在实验中,设置基域的大小为512 bit,在ZP中一个元素的大小|P|=160 bit,选择的挑战数据块数据量为c=460,每个数据块大小为2 KB,在不同数据块数量进行实验。
选取不同大小的文件,规定单个数据块大小为2 KB,文件分块数量从500 递增至3 000,分别计算各个方案的标签生成时间(如图2 所示)、证据生成时间(如图3 所示)、验证证据时间(如图4 所示)。
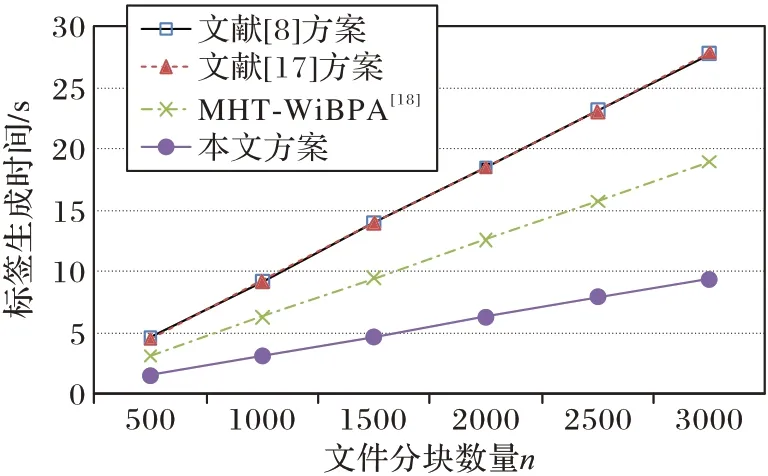
图2 标签生成时间Fig.2 Time of label generation

图3 证据生成时间Fig.3 Time of evidence generation
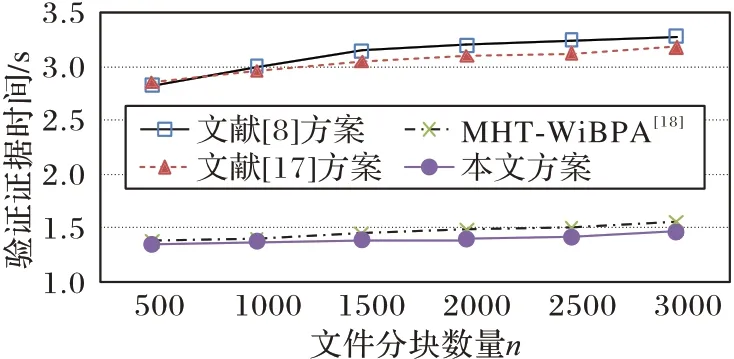
图4 验证证据时间Fig.4 Time of verifying evidence
根据实验对比,本文方案在标签生成、证据生成和验证证据3 个过程中,计算开销均有所下降。在证据生成阶段,由于本文计算证据无群元素参与,只涉及整数运算,故时间不到50 ms。其中本文方案与MHT-WiBPA 方案计算开销最为接近。相较于MHT-WiBPA 方案,在验证证据开销接近,但标签生成时间存在优势。计算本文方案与MHT-WiBPA 方案在6 次不同挑战块数量标签生成提高效率,从500、1 000、1 500、2 000、2 500、3 000 提高效 率分别约为50.07%、50.06%、50.10%、49.90%、49.50%、50.10%。对6 次提高效率取平均值,计算得本文标签生成时间比MHT-WiBPA 方案提高约49.96%。相较于其他方案,本文无双线性对参与,减少了群元素的计算,能够有效提高效率。
针对TPA 存在的恶意欺骗行为,本文利用伪随机比特生成器并增加用户与TPA 结果的交互过程,提出一种无双线性对的可信审计方案。本文方案中,利用伪随机比特生成器增强了挑战信息的随机性和时效性,解决了之前方案TPA 重复利用挑战信息的缺陷。用户通过对比TPA 的审计值自行判断数据完整性,有效抵抗TPA 的恶意审计行为。在方案设计过程中,减少了群元素的计算和无双线性对参与,利用实验证明了效率的提高;
但由于本文方案标签需用户自己生成,对用户计算能力要求较高,因此,本研究未来工作是构建一个标签外包计算的安全云审计方案。