解文涛 严嘉钰
(国网江苏省电力有限公司南京市江宁区供电分公司 江苏省南京市 211100)
常规的数据分析方法严重依赖人工方式进行特征建模,不仅效率低下,无法快速适应异常用电行为的变化,随着新能源持续高比例运行、电力电子装置大量应用,电力系统的动态非线性、多时间尺度、不确定性和难预测性表现得更加突出。
本文的主要研究思路如下,由于当前电量采集的异常用电数据和正常用电数据处于不平衡状态,因此,进一步的,不同类型导致的异常用电与实际正常用电的数据更是处于不平衡状态,可以说是极小样本。但是,这些用电异常成因产生的数据特征可以通过模拟仿真等方法,实现量产,从而改变机器学习的不平衡态势,因此,本项目的机器学习将采用小样本对抗学习模型,将前期正常与异常二分类深度学习的结果(识别的异常数据),进行深度多分类学习,这就需要用到小样本对抗学习模型。如图1所示,除了来自标准GAN框架的生成器G之外,BiGAN还包括编码器E,其将数据x映射到潜在表示z。BiGAN鉴别器D不仅在数据空间(x与G(z))中进行区分,而且在数据和潜在空间(元组(x,E(x))与(G(z),z))进行区分。即对于生成器生成的数据而言,其包含生成的数据和用以生成数据的噪声数据;
而对于真实数据而言,其包含数据本身和经过生成器逆映射得到的值。

图1:BIGAN示意图
因为BiGAN编码器学习预测给定数据x的特征,并且先前对GAN的工作已经证明这些特征能够捕获数据的语义属性,我们可以训练好的BiGAN编码器可以作为相关语义任务的有用特征表示,和在计算机视觉中完全监督的视觉模型训练好可以准确预测图像标签一样。在这种情况下,潜在表示z可以被认为是x的“标签”,但是不需要监督。BiGAN是一种强大且高度通用的无监督特征学习方法,不对其应用的数据结构或类型做出任何假设。
具体的思路如下,第一步将用电异常分类与可能导致的原因进行映射、分类;
第二步,建立不同异常用电原因下的深度对抗学习模型;
第三步,利用仿真、自编码的先进的对抗生成方法实现反例数据,输入对抗学习模型,使模型学到最优参数。第四步,对模型进行实际的应用数据验证。
同时,通过研究小样本学习技术,设计研发具备快速自学习能力的异常用电类型辨析算法,利用已知异常用电案例类型,结合计算机推算,形成大量学习样例,快速学习异常用电特性,生成更加详细、可信的异常用电诊断结果,为现场稽查、取证提供有力的支撑。同时,还可以更加科学的制定现场检验/检修计划,显著提升异常用电的检查效率。
本文提出了一种基于改进深度自编码网络的异常用电行为辨识方法,利用自编码器提取用电数据特征,在输出层重建输入数据,通过对比重构误差与检测阈值的差异实现异常行为的甄别。改进深度自编码网络由3个自编码器以贪婪训练的方式堆栈而成,为了提高网络的特征提取能力与鲁棒性,引入了稀疏约束和噪声编码,并由粒子群算法逐层优化网络的超参数。选择福建省某地区居民用电数据,验证了改进深度自编码网络模型的检出率高于92%,误检率低于5%。此外,基于不同异常比例的测试样本,验证了本文的模型克服了数据失衡问题;
基于不同采集频率的测试样本,验证了本文的模型改善了鲁棒性;
基于商业用电数据验证了模型的适用性。通过与自编码器、主成分分析、因子分析、神经网络、支持向量机和深度置信网络仿真对比分析,验证了改进深度自编码网络具有更好的特征提取能力和异常用电行为辨识能力。
具体的思路如下,第一步将用电异常分类与可能导致的原因进行映射、分类;
第二步,建立不同异常用电原因下的深度对抗学习模型;
第三步,利用仿真、自编码的先进的对抗生成方法实现反例数据,输入对抗学习模型,使模型学到最优参数。第四步,对模型进行实际的应用数据验证。
4.1 实验数据准备
4.1.1 数据的样本拆分与生成
首先,获取故障处理原始记录表格,获取用户数据,进行标签操作对历史表格进行统计,再由人工对照曲线进行二次确认,根据用户数据绘制的曲线如图2所示。
图2:基于用户数据绘制的曲线图
原始样本的维度主要包括:ABC三相电流、ABC三相电压。
所用用电数据的时间跨度为2018年1月1日至2020年10月31日,选择了约500个用户的异常用电记录,其中包括:一相欠压16户,一相失压20户,反接24户,一相欠流18户,一相失流65户。按照日进行分解,累计分解异常用电数据集(共15854条样本),比例约为4:6。其中,一相欠压2346条样本,一相失压3421条样本,反接2457条样本,一相欠流3731条样本,一相失流3899条样本,统计结果如图3所示。
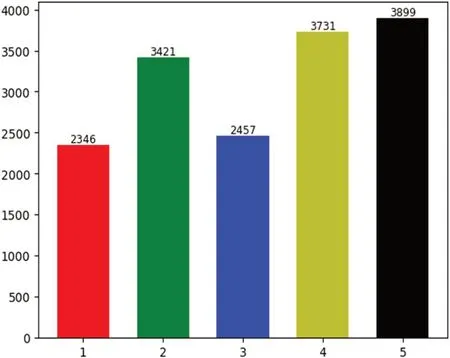
图3:针对用户用电数据得到的样本分布图
单一样本的采样点为95个,通过生成器与编码器进行处理后,样本平均采样点变为320个。
4.1.2 数据的训练集、测试集比例
训练集用于在每一个epoch中梯度下降(即训练模型的过程),而在每个epoch完成后,使用验证集来测试当前模型的准确率。在所有epoch训练完毕后,使用测试集测试整个模型(所有普通参数都更新完毕)的准确率等数据来对模型实际能力进行评估。
本次实验采用的训练集、验证集、测试集比例为7:1:5。考虑到项目的实际应用场景是一种小样本数据环境,在参考了关于深度学习的广泛实践经验基础上,对数据集比例进行了调整。适当提高的测试集的比例,使得模型更加高效率的找到高层次特征的拟合方向,可以较好地提高模型的训练速度。
4.2 训练过程
4.2.1 训练及测试校验
各数据集包含数据量如图4所示。

图4:各数据集包含的数据量分布图
模型训练过程中各异常类型(1~5)与正常类型(normal)判别正确率(acc)变化情况如图5所示。
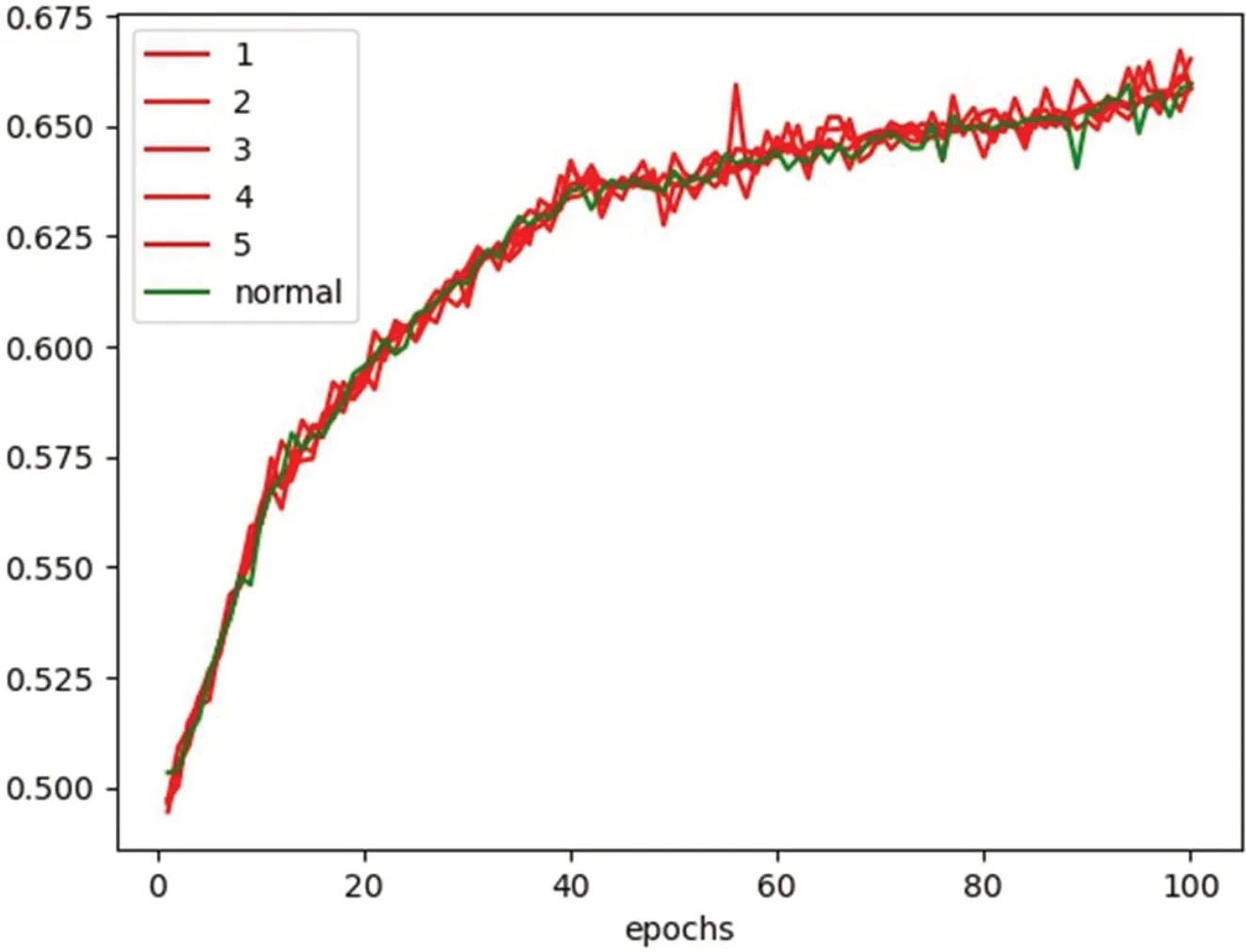
图5:各类异常数据训练结果变化情况图
4.2.2 问题及调优过程
模型在测试与训练遇到以下几种问题:
模型学习能力差,模型自身收敛速度过慢:其具体表现为模型参数震荡。经过调整,对模型的初始化权重与偏执进行了调整,更改了原始随机参数的生成方式,采用高斯分布随机数生成方式。同时调整了固定学习率的设置思路,采用动态调整学习率的adam算法。经过调整模型学习能力有所提升,收敛速度明显加快。
模型在训练过程中出现了轻微的过拟合:具体表现为模型在训练集上表现良好,但是在测试集上表现并不理想。在调整了数据集中训练集、测试集比例并且增加了一定比例的验证集后,模型过拟合现象消失,在测试集和验证集上均具有和在训练集上相符的表现。
经过多次测试和对模型的学习率模型的激活函数等目标函数的参数的调整。模型优化后正确率有一定程度的上升。
优化后的测试结果:
模型训练过程中各异常类型(1~5分别表示欠压失压)与正常类型(normal)判别正确率(acc)变化情况如图6所示。模型训练过程中损失值(loss)变化情况如图7所示。模型训练过程中F1-score变化情况如图8所示。
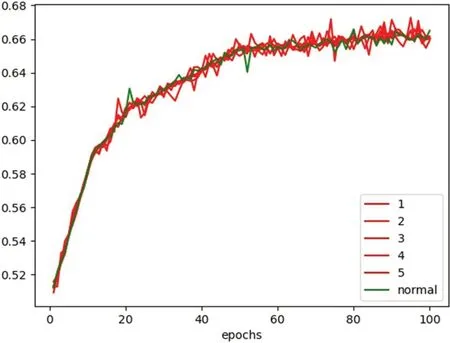
图6:欠压失压异常数据训练结果变化情况图

图7:模型训练过程中的损失值变化情况
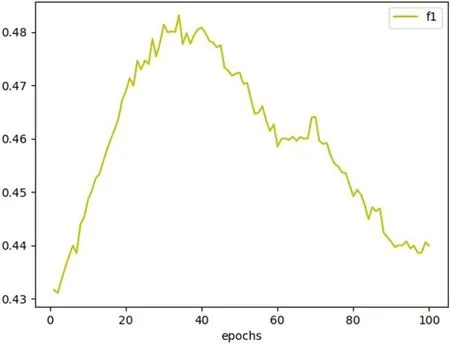
图8:模型训练过程中的F1得分变化图
4.3 测试结论
经过测试,模型学习能力良好,模型训练效率较高,模型拟合能力较强。可以较好的提取异常用电数据的高层特征,对于异常用电数据具有较好的分辨能力,正确率达到65%以上。最终的综合检测准确率为66.49%,综合检出率为65.34%,综合误检率为39.51%。
本文利用深度学习模型在当前样本较少情况下建立机器学习模型,目的在于能够在区分用电异常情况下,能够辨识出用户的大致用电异常种类,从而提高用电检查工作准确性和工作效率。由于当前计量中针对用户异常用电类型辨识的样本数据非常小,因此,项目采用了生成对抗深度学习方案,从实验数据和现场验证情况来看,获得了较好的效果,但是,随着科技的不断进步,异常用电与用户用电行为呈现越来越复杂的关系,很多异常用电的类型尚处于大类能区分,小类尚不能有效区分的状态,需要进行进一步的研究。从历年经验来看,很多用户的异常用电类型并非人为,大多是设备、计量、接线等问题导致,这为现场采集很多信息提供了可能,通过边缘代理设备接入更多的采集信息可以在辨识类型上更进一步,这为下一步的研究提供了有效的途径。
猜你喜欢编码器用电深度用煤用电用气保障工作的通知中国化肥信息(2021年12期)2021-04-19安全用电知识多中学生数理化·中考版(2020年12期)2021-01-18深度理解一元一次方程中学生数理化·七年级数学人教版(2020年11期)2020-12-14为生活用电加“保险”中学生数理化·中考版(2018年12期)2019-01-31深度观察艺术品鉴证.中国艺术金融(2018年8期)2019-01-14深度观察艺术品鉴证.中国艺术金融(2018年10期)2019-01-08用电安全要注意小学生必读(中年级版)(2018年10期)2019-01-04基于FPGA的同步机轴角编码器成都信息工程大学学报(2018年3期)2018-08-29深度观察艺术品鉴证.中国艺术金融(2018年12期)2018-08-26基于双增量码道的绝对式编码器设计制造技术与机床(2017年7期)2018-01-19